9. 그리고 새 프로젝트 만들기, c++ 검색, 빈 프로젝트 더블 클릭, 경로설정하고 만들기를 누른다.
10. 소스 파일 > 추가 > 새 항목 누르고 이름 설정 후. cpp로 추
11. 예제 테스팅 코드 입력
#include <opencv2/opencv.hpp>
using namespace cv;
int main()
{
int width = 500;
int height = 500;
Mat img(height, width, CV_8UC3, Scalar(0, 0, 0));
circle(img, Point(250, 250), 10, Scalar(255, 0, 0), -1);
circle(img, Point(250, 250), 100, Scalar(0, 0, 255), 1);
imshow("result", img);
waitKey(0);
}
12. 프로젝트 > 속성
13. 구성(C)는 Release에, 플랫폼(P)은 x64
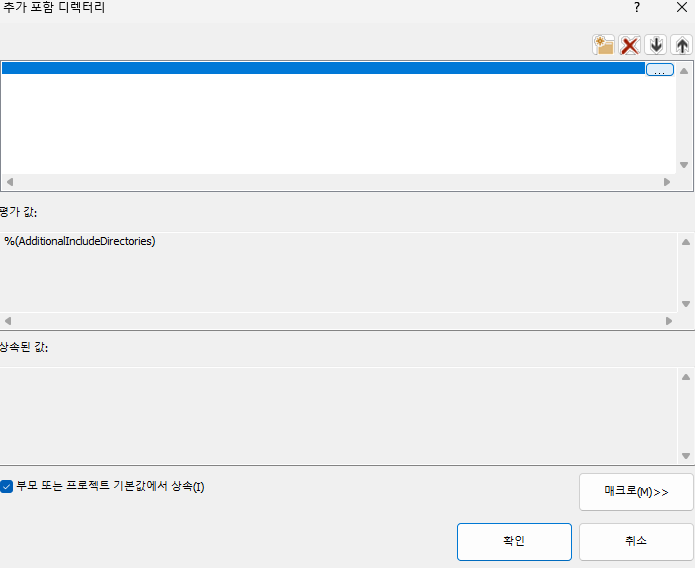
14. 왼쪽에서 C/C++을 찾아 일반을 누르고 추가 포함 디렉터리 맨 오른쪽 버튼을 누른 뒤 <편집...> 클릭
15. 줄 추가(폴더? 같은 노란색 버튼)을 누르고 맨 위 줄을 한 번 클릭해 보면 맨 오른쪽에 ... 버튼이 생긴다. 그걸 누르고 opencv/build에 들어가 include를 한 번 클릭한 뒤에 폴더 선택 버튼 후 확인
16. 왼쪽 스크롤에서 링커 > 일반 > 추가 라이브러리 디렉터리 한 번 클릭 후 맨 오른쪽 버튼 > <편집...>버튼
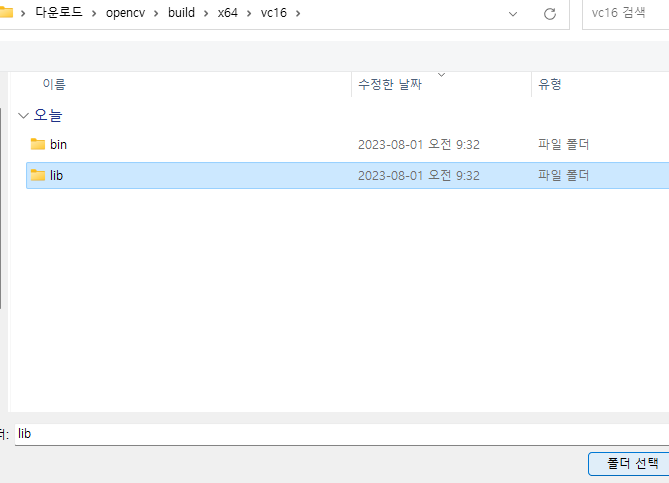
17. 또 아까처럼 줄 추가 버튼 후 경로 선택 버튼 그리고 opencv/build/x64/vc16(버전에 따라 15,14)에 들어가고 lib를 한 번만 누른 다음에 폴더 선택 버튼을 누른 뒤 확인
18. 왼쪽 스크롤에서 링커의 입력에 들어간 뒤 추가 종속성에서 오른쪽 버튼 후 <편집...>
19. opencv/build/x64/vc16/lib에 들어가 opencv_world480.lib를 복사한다. 버전에 따라 opencv_world455.lib 등 숫자가 다를 수 있다. 그러면 그 숫자로 하면 된다. opencv_world480d.lib는 디버깅 모드를 위한 lib이다. 지금은 릴리스 모드를 위한 세팅이기 때문에 이렇게 해준다.
19. 그리고 17번 통해 들어간 추가 종속성에 opencv_world480.lib를 붙여넣기하고 확인을 눌러준다. 그리고 또 확인을 눌러 설정 탭을 닫아준다.
20. Release 모드로 바꾼 뒤에 ctrl F5를 눌러 빌드 후 실행을 해본다. 그러면 opencv_world480.lib가 없다면서 에러가 뜨는데 재부팅하고 다시 실행해 준다.
셀레니움을 하다가 드라이버 호환성 때문에 구버전 크롬을 다운로드해야 되는 상황이 생겨 다운로드하다가 심심해서 구버전 레지스트리를 건드렸다.
그러고 나서 Chrome을 접속하니 Couldn't lunch Chrome, google chrome cannot read and write to its data directory 오류가 생겨, Chrome에 접속하기 위해서 이를 해결을 해야 하는 상황이 나왔다. 한국어로 착하게 해결법을 알려주는 포스팅이 없어 내가 써야겠다고 생각했다.
프로그램 추가/제거에서 삭제하고 신버전을 다시 깔아도 결과는 같았다.
백신 같은 거 잠깐 끄고 설치하거나 안전 모드로 실행해도 결과는 같았다. 그럼 어떻게 해야 할까?
레지스트리 설정을 초기화 시켜야 한다. 프로그램 추가/제거로 chrome을 제거해도 chrome에 대한 레지스트리는 남아있기 때문이다.
해결 방법
1. 프로그램 추가/제거에서 chrome을 검색 후 삭제한 뒤 google도 검색해서 google 관련한 안 쓰는 모르는 건 다 지워준다.
2. window 단축키를 눌러 레지스트리 편집기라고 쳐보자
3. 레지스트리 편집기에 접속해서 HKEY_LOCAL_MACINE/SOFTWARE/Policies/Google에 들어가 Chrome 폴더를 삭제해 준다.
4. Chrome을 다시 깔고 재부팅을 한다. 그럼 해결된다.
크롬 드라이버 혹은 크롬 구버전 설치
Chrome을 다 지우고 아래 링크를 통해서 크롬 드라이버나 크롬 구 버전을 설치할 수 있다.
.index: DataFrame 또는 Series에서 인덱스를 참조한다. 데이터 구조의 행에 접근하는 데 사용된다. .set_index(keys): DataFrame에서 특정 열을 인덱스로 설정하다. keys에 지정된 열이 새로운 인덱스로 사용된다.
head(n=5): DataFrame 또는 Series의 처음 n행을 반환한다. n을 지정하지 않으면 기본적으로 처음 5행을 보여준다.
.describe() 함수는 pandas DataFrame 또는 Series의 기술 통계량을 요약하여 보여준다. 기본적으로 수치형 데이터에 대한 요약 통계량을 반환하며, 이에는 평균(mean), 표준편차(std), 최솟값(min), 최댓값(max), 사분위수(25%, 50%, 75%) 등이 포함된다.
문자열이나 카테고리형 데이터가 포함된 경우, .describe(include=['object', 'category'])와 같이 include 매개변수를 사용해 요약 정보를 얻을 수 있다. 이 경우, 유니크한 값의 개수(count), 가장 흔한 값(top), 그 값이 나타나는 빈도(freq) 등의 정보를 포함한다.
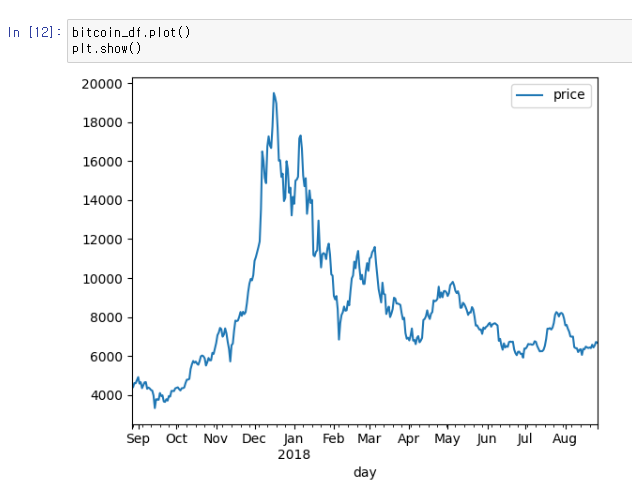
plot() 함수는 데이터 시각화 라이브러리인 Matplotlib에서 데이터를 그래프로 그리기 위해 사용된다. plt.show()는 그려진 그래프를 화면에 표시하다. 예를 들어, X축과 Y축 데이터 간의 관계를 선 그래프로 나타내고자 할 때 plot() 함수를 사용하고, 최종적으로 그래프를 보기 위해 plt.show()를 호출한다.
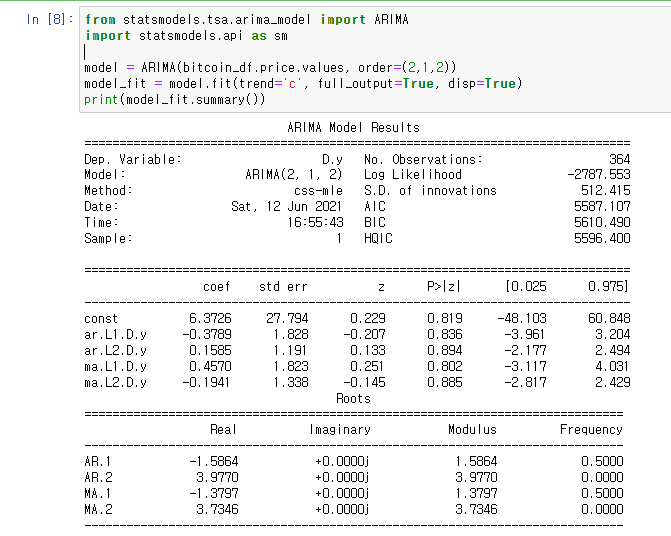
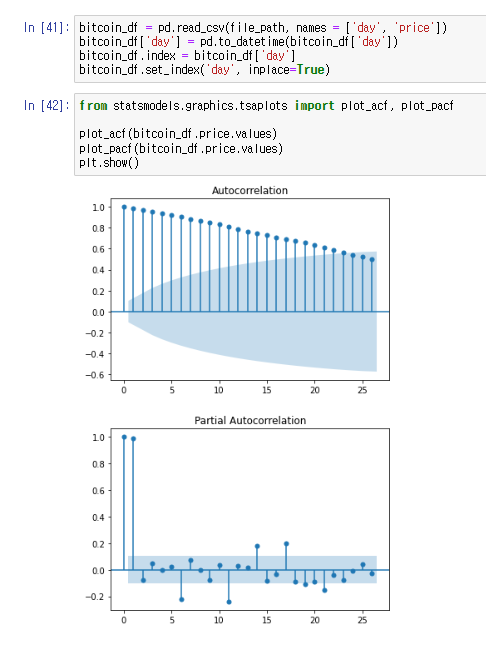
ARIMA 모델은 시계열 데이터를 분석하고 예측하기 위한 통계적 방법이다. ARIMA는 AutoRegressive Integrated Moving Average의 약자로, 세 가지 주요 구성 요소로 이루어져 있다.
자기 회귀(AR: AutoRegressive): 모델이 이전 관측값의 의존성을 설명한다. 파라미터 p는 과거 관측값이 현재 값을 예측하는 데 사용되는 시차의 수를 나타낸다.
차분(I: Integrated): 비정상성을 제거하기 위해 원 시계열 데이터에 차분을 적용하는 과정을 말한다. 파라미터 d는 데이터가 정상성을 달성하기 위해 필요한 차분의 횟수를 나타낸다.
이동 평균(MA: Moving Average): 모델이 이전 예측 오차의 의존성을 설명한다. 파라미터 q는 과거 예측 오차가 현재 값을 예측하는 데 사용되는 시차의 수를 나타낸다.
학습 데이터에 대한 예측 결과
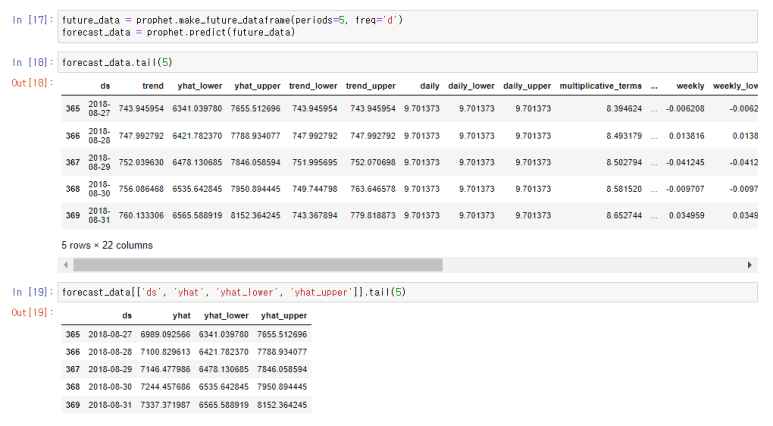
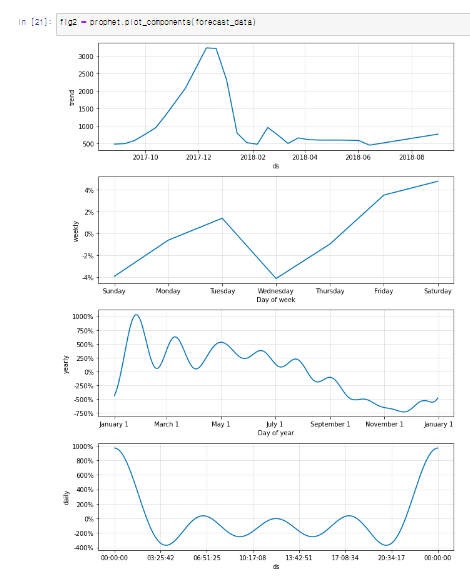
prophet 모델
Prophet 모델은 Facebook에서 개발한 시계열 예측을 위한 도구다. 주로 일일 활동 패턴, 주간 및 연간 계절성 등이 명확한 시계열 데이터에 대한 예측에 적합하다. Prophet은 특히 휴일 효과나 이벤트가 예측에 중요한 역할을 하는 경우에 유용하며, 누락 데이터나 이상치가 있는 데이터셋에서도 견고한 예측 성능을 보인다.
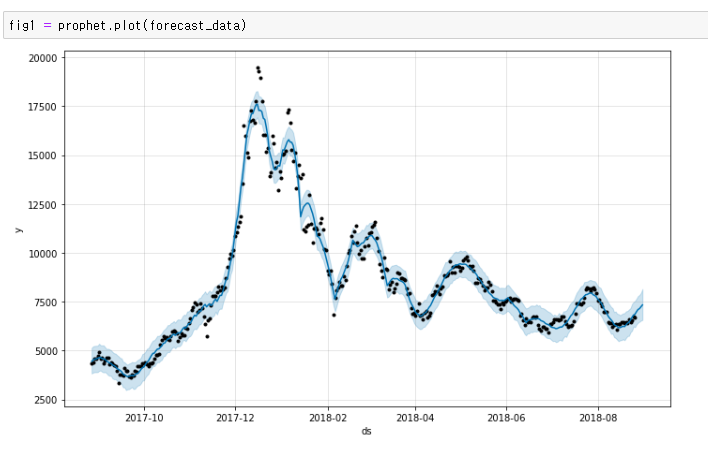
위 사진 2개가 prohet 모델이며 페이스북에서 라이브러리를 오픈하여 그걸 이용한 모델이다. 간편한편 이며 직관적인 api를 제공하며 유연성과 확장성이 높은 모델이다. 대신 외생 변수를 직접적을 처리하기 어렵고 과거 데이터의 의존하는 경향이 있다.
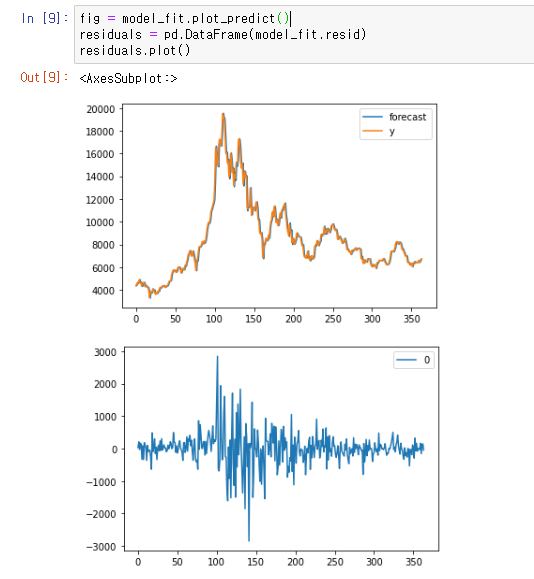
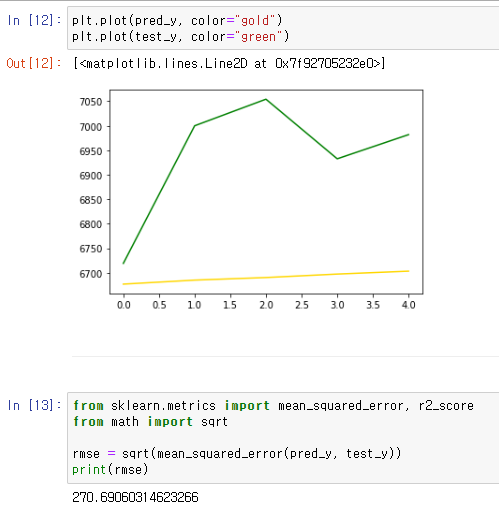
골드는 예상한 가격 그래프, 그린은 실제 가격 그래프
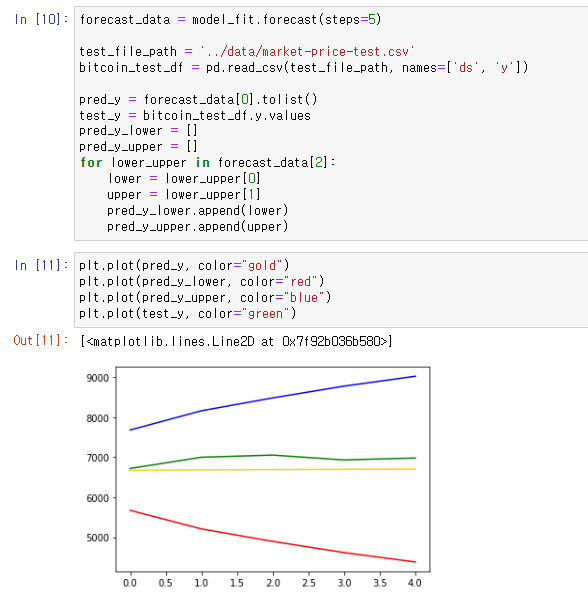
골드는 예상한 가격 그래프, 레드는 최소 가격 그래프(예상), 블루는 최대 가격 그래프(예상), 그린은 실제 가격 그래프 (잔차의 변동을 시각화)
위쪽 2장의 사진은 arima 모델을 사용한것이고 제일 아래쪽 사진이 statsmodel 모델을 사용한것 이다.
ARIMA는 시계열 데이터 분석에 사용되는 모델이며 ARIMA 모델은 데이터의 자기 상관성과 추세를 모델링하여 미래 값을 예측하는데 사용된다.
이 모델은 적절한 파라미터 조정과 데이터 전처리를 통해 높은 예측 정확도를 제공하며 계절성이나 추세 등의 시계열 패턴을 캡처하는 데 유용하다.
대신 단기예측에 적합해서 장기적인 예측은 제한적이며 경제 지표나 기상정보등 외생변수를 처리하기 어려운 부분이 있다.
statsmodels는 많은 종류의 통계 모델 피팅, 통계 테스트 수행, 데이터 탐색과 시각화를 위한 라이브러리이다. 이 모델은 통계 분석에 특화가 된 모델이며 가설감정 및 추론을 위한 다양한 감정 기능을 제공한다. 대신 데이터 전처리 기능이 제한적이며 시각화를 위한 기능이 제한적이다.
다양한 모델을 이용한 시각화 그래프를 다루고 사용해 봤는데 가장 실제값과 예측값이 잘맞은것은 prophet 모델을 이용한 시각화 그래프 였다.
prophet모델은 연간, 월간, 주간, 일간 등의 주기적 변화를 모델링한다. Fourier series를 사용해 복잡한 계절성 패턴을 유연하게 캡처할 수 있다. 또한, 공휴일이나 특별 이벤트 등 예측 대상 시계열 데이터에 영향을 미치는 날짜를 모델링한다. 사용자가 직접 휴일과 이벤트 날짜를 지정할 수 있다.
데이터 불러오기: start_date와 end_date를 설정하여 원하는 기간의 비트코인 가격 데이터를 가져온다.fdr.DataReader() 함수를 사용하여 데이터를 가져온다. 가져온 데이터 중에서 'Close' 컬럼의 값만 선택하여 변수 close_data에 저장한다.
데이터 전처리: MinMaxScaler()를 사용하여 데이터를 0과 1 사이의 범위로 스케일링한다. 스케일링된 데이터는 변수 scaled_data에 저장된다.
이동 평균선 계산: 이동 평균을 계산하기 위해 np.convolve() 함수를 사용한다. moving_avg에 이동 평균선 데이터가 저장된다.
데이터셋 생성 함수: create_dataset() 함수는 입력 데이터와 레이블 데이터를 생성하는 함수이다. 입력 데이터는 이전 일 수(lookback)에 해당하는 데이터로 구성된다.
실제 가격과 예측 가격 비교: df_predictions 데이터프레임에 실제 가격과 예측 가격을 저장한다. 예측 결과를 출력한다.
데이터 분할: 생성한 데이터셋을 훈련 데이터와 테스트 데이터로 분할한다.
테스트 데이터 예측: 테스트 데이터의 마지막 값(마지막 10일의 가격)을 예측 값으로 사용한다.
scaler.inverse_transform() 함수를 사용하여 예측 값을 원래 스케일로 변환한다.
plt.figure() 함수를 사용하여 그래프의 크기를 설정한다.
plt.xlabel(), plt.ylabel(), plt.title() 함수를 사용하여 축 레이블과 그래프 제목을 설정한 후 legend와 show함수를 이용하여 그래프와 범례를 표시한다.
예측 가격 그래프, 이동 평균선 그래프, 추세 그래프를 차례로 그린다.
위 그래프는 LSTM은 RNN의 일반적인 문제인 장기 의존성 문제(Long-Term Dependency Problem)를 해결하기 위해 제안된 모델이며 시계열 데이터나 자연어 처리와 같이 시간적인 의존성을 가진 데이터를 처리하는 데에 주로 사용된다.
가장 큰 장점으로는 입력의 길이에 따라 동적으로 확장되거나 축소되는 특성을 가지고 있어, 자연어 처리와 같이 문장의 길이가 다양한 작업에 적합하다. 대신 그만큼 단점으로는 계산 비용이 높고, 모델 구조가 복잡하여 사용하기 어렵다는 게 가장 큰 문제라고 할 수 있다.
import FinanceDataReader as fdr
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
#데이터 불러오기
start_date = '2018-01-01'
end_date = '2022-12-31'
bitcoin_data = fdr.DataReader('BTC/KRW', start_date, end_date)
#데이터 추출
close_data = bitcoin_data['Close'].values.reshape(-1, 1)
#데이터 스케일링
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(close_data)
#데이터 분할
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
test_data = scaled_data[train_size:]
#LSTM 입력 데이터 생성
def create_dataset(data, lookback):
X, Y = [], []
for i in range(len(data) - lookback):
X.append(data[i:(i + lookback), 0])
Y.append(data[i + lookback, 0])
return np.array(X), np.array(Y)
lookback = 10 # 이전 10일의 데이터를 기반으로 예측
X_train, Y_train = create_dataset(train_data, lookback)
X_test, Y_test = create_dataset(test_data, lookback)
#LSTM 모델 구성
model = Sequential()
model.add(LSTM(32, input_shape=(lookback, 1)))
model.add(Dense(1))
#모델 컴파일 및 학습
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, Y_train, epochs=50, batch_size=16)
#테스트 데이터를 사용하여 예측
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
#실제 데이터와 예측 데이터 비교
df_predictions = pd.DataFrame(predictions, columns=['Predictions'])
df_predictions['Actual'] = scaler.inverse_transform(Y_test.reshape(-1, 1))
print(df_predictions)
결과값 :
Predictions Actual
0 50284368.0 50108356.0
1 50338856.0 50834512.0
2 50911044.0 52121544.0
3 52035676.0 50548744.0
4 51556176.0 51299848.0
.. ... ...
351 22036330.0 21274356.0
352 21884058.0 21097826.0
353 21707998.0 20980342.0
354 21548640.0 20950968.0
355 21451494.0 20881450.0
[356 rows x 2 columns]
시각화
import matplotlib.pyplot as plt
#테스트 데이터를 사용하여 예측
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
#실제 데이터와 예측 데이터 비교
df_predictions = pd.DataFrame(predictions, columns=['Predictions'])
df_predictions['Actual'] = scaler.inverse_transform(Y_test.reshape(-1, 1))
CDN은 전 세계에 분산된 서버 네트워크를 통해 웹 컨텐츠를 빠르게 제공하는 시스템이다. 사용자가 요청하는 웹 컨텐츠를 사용자에게 가장 가까운 서버에서 제공함으로써, 로딩 시간을 줄이고 사용자 경험을 개선한다. CDN은 웹사이트의 정적 컨텐츠(이미지, 스타일시트, 자바스크립트 파일 등)를 효율적으로 전송하는 데 자주 사용된다.
최초 사용자가 content를 요청하면 Edge Pop Server가 Origin Server에 데이터를 요청하고 Edge Pop server가 받은 데이터를 다시 최초 사용자에게 돌려준다. 그 후 이용하는 사용자들은 Edge Pop서버에서 데이터를 받을 때 Edge Pop에는 이미 Origin Server에서 받은 데이터가 있으므로 굳이 Edge Pop과 Origin Server의 데이터 송수신을 안 해도 되고 이후 사용자와 Edge Pop서버의 데이터 송수신만이 이루어진다.
이렇게 되면 Origin Server와의 거리가 먼 사용자에게도 빠르게 content를 전달할 수 있고 Edge Server에서 content를 캐싱 하여 원본 부하가 줄고 콘텐츠 제공할 때 생기는 금액도 절약할 수 있다. 국내 서비스에서는 굳이 CDN이 필요가 없다. 비용 절감 면에선 필요하지만 기능상 크게 없어도 된다. 국내에서 데이터를 송수신하게 되면 거리가 짧기 때문에 중간 Edge Server가 크게 필요 없다, Starcraft나 League of Legends라는 온라인 PC 게임을 한국에서 외국 서버로 접속했을 때 거리가 멀기 때문에 ms 차이가 발생하는데, 이 ms 차이를 줄이기 위해선 CDN이 필수적이지만 국내에선 ms 차이가 나지 않기 때문에 리소스 비용 절감 등 비용적인 면으로만 사용하면 된다고 생각하면 될 것 같다.
CDN은 Microsoft, Verizon, Akamai에서 제공하고 있고 각 기능별로 가격이 다른 Standard, Front Door, Premium 등 다양한 버전이 있다. CDN은 Profile과 Endpoint와 캐싱 개념이 중요하고 Domain, SSL, CORS, TTL 등을 기능에 맞게 커스텀 하는 게 중요하다.
ECF(Exceptional Control Flow)를 알기 전에 여러가지 기초 지식이 많이 요구된다. 이를 알지 못하면 ECF를 이해하기 힘들기 때문이다.
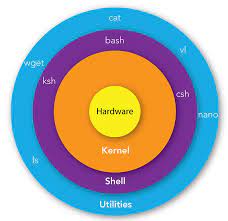
컴퓨터 구조의 가장 안쪽에 CPU, 메모리, 프린터, 램카드 등의 하드웨어들이 있다. 이 묶음을 자원들이라고 하고 이를 application에 할당하는게 OS이다.(자원관리) OS안에는 cpu를 관리하는 프로세스 관리, 메모리 관리, I/O관리를 하는 것은 커널에 해당한다. 쉘은 사용자가 명령을 내리면 그 명령을 해석하여 결과를 반응하여 보여준다.(명령어 해석기)
패킷은 네트워크상에서 전송될 데이터들의 덩어리이다. 사용자 데이터와 제어정보로 나뉘는데 사용자 데이터는 페이로드라고 한다. 제어정보는 소스와 목적지에 대한 네트워크 주소, 순서 정보, 오류 감지 코드로 분류된다.
프로세스 문맥은 어떤 상태에서 수행되고 있는지, 규명하기위해 필요한 정보이다. 시분할로 프로세스를 한 번씩 실행시킬 때, 어디까지 실행됐는지, 메모를 해놔야 한다. 이 때 프로세스 컨텍스트를 사용한다. 프로세스 문맥은 하드웨어 문맥, 프로세스의 주소공간, 커널상의 문맥으로 분류된다. 프로세스의 제어권을 넘겨주는 것은 컨텍스트 스위칭이라고 한다.
그럼 CPU의 제어권을 넘겨 커널모드로 진입하게 하는 것은 무엇일까? 주로 인터럽트, 트랩에 의한 시스템콜이다.
시스템 콜(System Call)은 사용자 프로그램이 운영 체제의 커널 서비스를 요청할 때 사용하는 인터페이스이다. 운영 체제는 하드웨어 자원을 관리하고, 다양한 기본 서비스를 제공하는 소프트웨어의 집합이다. 사용자 프로그램은 직접적으로 하드웨어 자원에 접근할 수 없으므로, 시스템 콜을 통해 안전하게 이러한 자원과 서비스를 요청하고 사용한다.
시스템 콜의 주요 기능
프로세스 관리: 프로세스 생성, 실행, 종료, 스케줄링 등의 관리 작업을 수행한다.
파일 시스템 조작: 파일 생성, 삭제, 읽기, 쓰기, 열기, 닫기 등의 파일 시스템 관련 작업을 수행한다.
장치 관리: 하드웨어 장치에 대한 접근 및 제어를 수행한다.
정보 유지: 시스템 날짜 및 시간 설정, 시스템 데이터 조회 등의 작업을 수행한다.
통신: 프로세스 간 통신(IPC)이나 네트워크 통신을 위한 메커니즘을 제공한다.
시스템 콜의 작동 방식
시스템 콜 요청: 사용자 프로그램은 특정 작업을 수행하기 위해 시스템 콜을 호출한다. 이 때, 필요한 매개변수를 제공한다.
커널 모드 전환: 시스템 콜이 호출되면, CPU는 사용자 모드에서 커널 모드로 전환된다. 커널 모드에서는 운영 체제가 전체 시스템 자원에 대한 전체 제어 권한을 가진다.
시스템 콜 처리: 운영 체제 커널은 요청된 시스템 콜에 따라 필요한 작업을 수행한다.
사용자 모드로 복귀: 작업이 완료되면, 시스템은 사용자 모드로 다시 전환되고, 프로그램은 시스템 콜 결과를 받아 계속해서 실행된다.
프로그램 카운터의 연속된 값 예를 들어 l(k)에 대응하는 a(k), a(k+1)이 있을 때 a(k) - > a(k+1) 이렇게 다음으로 넘어가는게 제어이동이라고 한다. 이런 제어이동의 배열은 제어흐름이라고 한다.
I(k)와 I(k+1)이 나란히 있는 경우는 점진적인 순서라고 하고, 이 둘이 인접하지 않고 jump, call, return에 의해 갑작스런 변화가 발생할 때가 있다. 저런 명령어들은 꼭 프로그램을 작성하면서 필요하여, 예외적인 제어 흐름이 발생할 수 밖에 없는데, 컴퓨터는 이런 예외적인 제어 흐름에도 반응할 수 있어야 한다.
패킷들은 네트워크 어댑터에 도착하고 메모리에 저장되어야한다. 프로그램은 디스크로부터 데이터를 요청하고, 데이터가 준비됐다는 말이 나올 때까지 대기한다. 하드웨어에서 검출된 이벤트는 예외 핸들러로 갑작스런 제어이동을 발생한다. ECF는 운영체제가 입출력, 프로세스, 가상메모리를 구현하기 위해 사용한다. trap, system call을 이용하여 응용프로그램이 호출한다.
예외상황 - 예외적인 제어흐름의 한가지 형태
하드웨어와 소프트웨어의 예외상황 분류는 불필요함
예외의 분류:
인터럽트 : 비동기적으로 하드웨어 장치로부터 발생하는 신호 혹은 외부 이벤트가 발생했음(트랩은 인터럽트의 종류지만, 동기적)을 알리는 신호이다. CPU가 현재 처리 중인 작업을 잠시 중단하고, 긴급하게 처리해야 하는 작업이다. 보통 하드웨어 장치에서 프로세서로 시스템 콜을 보내 커널모드로 전환되게 한다.(어보트는 인터럽트의 종류지만, 시스템 콜과 직접적인 관련이 없다.)
트랩 : 특정 명령어 실행에 의해 CPU의 제어 논리가 운영 체제의 커널 기능을 요청하기 위해 의도적으로 생성하는 예외이다. 프로그램 실행과 동기적이다. 명령 스트림에 대해 잘 정의된 시점에서 발생하고 시스템 콜, 디버깅을 목적으로 사용한다. 운영 체제가 프로그램을 대신하여 파일 읽기를 수행한다. (0으로 나누기, 잘못된 메모리 접근에 대한 처리)
폴트 : 핸들러로 인해서 복구가 가능하고 수정될 수 있는 예외이다. 프로세서가 명령을 실행하려고 할 때 오류 조건을 감지하고, 메모리 접근 중 페이지 폴트와 같은 오류가 발생 했을 때 발생한다. 페이지 폴트는 프로그램이 현재 물리 메모리 접근 할 때 일어난다. 가상 메모리의 적절한 부분을 물리 메모리로 로딩 함으로써, 프로그램은 폴트가 전혀 발생하지 않은 것처럼 실행을 재개할 수 있다. (세그먼트 폴트, 페이지 폴트)
어보트 : 복구할 수 없는 오류 조건을 나타낸다. 하드웨어 실패 또는 하드웨어가 감지하고 복구할 수 없는 메모리 시스템의 불일치와 같은 하드웨어 또는 시스템 환경의 심각한 문제를 지시한다. (ASSERT)
예외가 발생하면, 프로세서는 적절한 예외 핸들러로 제어를 이전해야 한다.
자세한 내용은 Process, Thread를 다룰 때 추가로 포스팅할 예정이다.
예외 처리 과정
예외 감지: 예외 처리의 첫 단계는 예외가 발생했음을 감지하는 것이다. 이 감지는 CPU의 정상적인 명령 실행 과정의 결과로 발생한다. 예를 들어, 응용 프로그램이 0으로 나누려고 하면, CPU는 나눗셈 연산을 실행하려고 할 때 이를 감지한다.
예외 분류: 예외가 감지되면, 시스템은 여러 범주 중 하나(인터럽트, 트랩, 폴트, 어보트)로 분류한다. 이 분류는 시스템이 예외를 어떻게 처리할지 결정하기 때문에 중요하다.
컨텍스트 저장: 프로세서가 예외 핸들러의 실행을 시작하기 전에, 예외가 처리된 후에 복원할 수 있도록 현재 컨텍스트(CPU의 상태)를 저장해야 한다. 이것은 보통 레지스터, 프로그램 카운터 및 기타 중요한 상태 정보를 저장하는 것을 포함한다.
예외 처리 루틴: 프로세서는 인터럽트 벡터 테이블 또는 예외 테이블이라고 하는 사전에 정의된 테이블을 사용하여 예외를 해당 핸들러의 메모리 주소에 매핑한다. 그런 다음 프로세서는 프로그램 카운터를 핸들러의 주소로 변경하여 핸들러 루틴에 제어를 효과적으로 이전한다.
핸들러 실행: 예외 핸들러가 실행되고 예외를 처리하기 위해 필요한 모든 작업을 수행한다. 이것은 잘못된 프로그램을 종료하거나, 프로세스에 시그널을 보내거나, 오류를 수정하고 작업을 다시 시도하거나, 디버깅 목적으로 오류를 기록하는 것을 포함할 수 있다.
예외에서 복귀: 예외가 처리된 후에는 시스템이 정상적인 실행 흐름으로 돌아가야 한다. 예외가 트랩이나 인터럽트였다면, 시스템은 예외를 발생시킨 명령 바로 다음 명령으로 돌아갈 수 있다. 폴트가 수정되었다면, 시스템은 폴트가 발생한 명령을 다시 시도할 수 있다. 어보트였다면, 시스템은 프로그램으로 전혀 돌아가지 않고 대신 종료할 수 있다.
컨텍스트 복원: 마지막 단계는 저장된 컨텍스트를 복원하여 프로세스나 프로그램이 예외가 발생하지 않은 것처럼 계속 실행될 수 있도록 하는 것이다. 이것은 예외가 감지될 때 저장된 정보로부터 CPU 상태를 복원하는 것을 포함한다.
시그널은 소프트웨어 단에서 이벤트를 통지하지만 인터럽트는 하드웨어 단에서의 이벤트 처리를 할 때 발생한다. 둘이 비슷해 보일 수 있지만, 운영체제의 컨텍스트에서 서로 다른 메커니즘을 가리킨다. (ctrl+C로 배시 창 나가기, kill PID)
시그널은 다양한 이유로 발생할 수 있다. 예를 들어, 사용자가 프로세스를 종료하려고 할 때(SIGINT), 프로세스가 접근할 수 없는 메모리에 접근하려고 할 때(SIGSEGV), 알람 타이머가 만료되었을 때(SIGALRM) 등
시그널이 발생하면 그 자체로 시스템 콜을 발생시키는 것은 아니다. 그러나 시그널 처리 과정에서 프로세스는 특정 시그널에 대응하기 위해 시스템 콜을 사용할 수 있다. (시스템 콜을 활용한 시그널 핸들러 설정) 그리고, 시그널을 명시적으로 보내는 행위 kill() 같은 것은 시스템 콜을 통해 이루어진다.
시그널 자체는 시스템 콜을 직접적으로 발생시키지는 않지만, 시그널 처리 메커니즘은 시스템 콜과 밀접하게 관련되어 있으며, 프로세스는 시그널을 처리기 위해 시스템 콜을 사용할 수 있다.
인터럽트는 하드웨어 이벤트 또는 소프트웨어 명령에 의해 발생하며, 시스템 전체에 영향을 줄 수 있다. 반면, 시그널은 특정 프로세스에게 전달되는 비동기적 이벤트나 예외 상황을 나타낸다.
인터럽트는 주로 운영 체제의 인터럽트 핸들러가 처리하며, 시그널은 대상 프로세스가 직접 처리한다.
인터럽트는 시스템의 반응성과 동시성을 높이는 데 초점을 맞추고 있으며, 시그널은 프로세스에게 비동기적인 사건이나 예외 상황을 알리는 데 사용된다.
일반적인 삽입만 했다면, 맨 위의 5가지 규칙이 깨지지 때문에 이를 규칙에 맞게 다시 재조정할 필요가 있다.
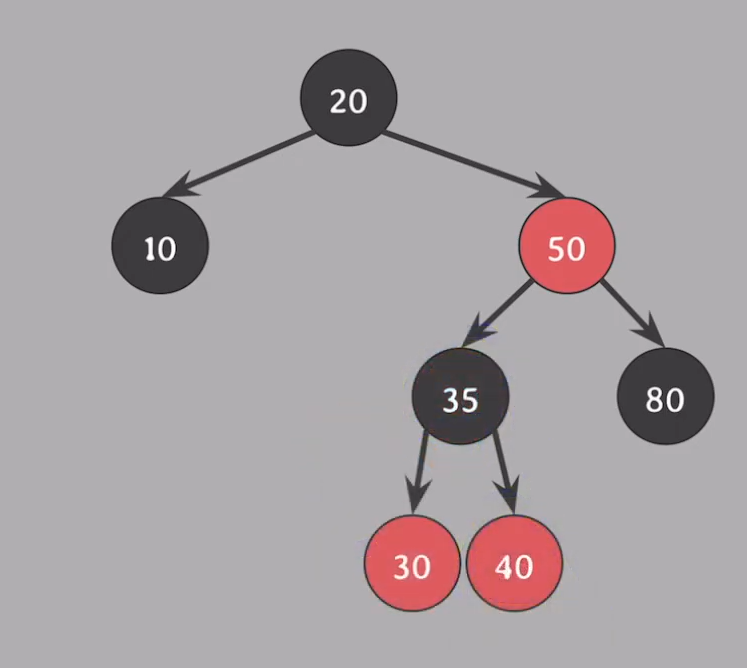
위의 시뮬레이터로 계속 삽입을 하면 보이다 싶이, 결국 black 노드가 많아지는 것을 볼 수가 있다.
위 사진에서 insert(25)를 해보자.
그럼 30의 좌측 자식 red노드로 처음엔 삽입될 것 이다. 이는 5가지 규칙 중 노드가 red라면 자녀들은 black을 위반한 상태이다. 부모와 삼촌을 black으로, 할아버지는 red로 변경하고 할아버지인 35에서 확인해보자 50 > 35가 레드가 되니 노드가 red라면 자녀들은 black을 위반한 상태이다. 그러면 50을 기준으로 오른쪽으로 회전해보자
그러면 또 35와 50을 보면 문제가 생기는데, 20과 35의 색깔을 바꿔주고 20을 기준으로 왼쪽으로 회전하면 된다.
이진탐색트리는 binary search와 linked list를 결합한 자료구조이다. 이진 탐색의 효율적인 탐색 능력을 유지하면서도, 빈번한 자료 입력과 삭제를 가능하게끔 고안되었다.
이진탐색의 경우 탐색에 소요되는 계산 복잡성은 O(logN)으로 빠르지만 자료 입력, 삭제가 불가능하다. 연결 리스트의 경우에는 자료 입력, 삭제에 필요한 계산복잡성은 O(1)로 효율적이지만, 탐색하는 데에는 O(n)의 계산 복잡성이 발생한다.
각 노드의 왼쪽 서브트리에는 해당 노드의 값보다 작은 값을 지닌 노드들로 이루어져 있다.
각 노드의 오른쪽 서브트리에는 해당 노드의 값보다 큰 값을 지닌 노드들로 이루어져 있다.
중복된 노드가 없어야 한다.
왼쪽 서브트리, 오른쪽 서브트리 또한 이진탐색트리이다.
이진탐색트리를 순회할 때는 중위순회(inorder) 방식을 쓴다. (왼쪽 서브트리-노드-오른쪽 서브트리 순으로 순회) 중위순회 방식을 사용하면 이진탐색트리 내에 있는 모든 값들을 정렬된 순서대로 읽을 수 있다. (1,5,6,10,14,17,21)
이진탐색트리의 핵심 연산은 검색, 삽입, 삭제 세 가지이다. 이밖에 이진탐색트리 생성, 이진탐색트리 삭제, 해당 이진탐색트리가 비어 있는지 확인, 트리순회 등의 연산이 있다.
탐색(검색)
이진탐색트리의 탐색 연산에 소요되는 계산복잡성은 트리의 높이(루트노드-잎새노드에 이르는 엣지 수의 최대값)가 h일 때 O(h)가 된다.
삽입
트리가 매우 적으면 그냥 중간에 삽입하면 되는데, 매우 길어질 때를 방지하기 위하여, 새로운 삽입은 무조건 리프노드에서 이루어지게된다. 삽입 연산에 소요되는 계산복잡성 역시 트리의 높이가 h일 때 O(h)이다. 삽입할 위치의 리프노드까지 찾아 내려가는 데 h번 비교를 해야 하기 때문이다.
삭제할 때의 경우
자식노드가 없는 경우 - 그냥 삭제하면 된다.
자식노드가 하나 있는 경우 - 본인을 삭제하고 부모와 자식을 연결하면 된다.
자식노드가 두 개 있는 경우 - 아래 과정을 따른다.
자식노드가 두 개 있을 때 삭제 과정
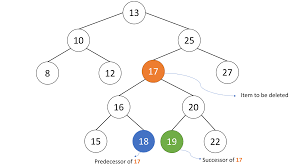
삭제 대상 노드의 오른쪽 서브트리를 찾는다.
successor 노드를 찾는다.
2에서 찾은 successor의 값을 삭제 대상 노드에 복사한다.
successor 노드를 삭제한다.
successor란? 중위 순회를 나열한 배열에서 본인의 바로 다음에 있는 노드이다. 즉 본인보다 오른쪽에 있으면서, 가장 작은 노드이다. (맨위 사진에서 [1,5,6,10,14,17,21] 여기서 10의 successor는 14이다.)
17 우측에 있는 노드 중에 가장 작은 19가 successor이다.
트리의 높이가 h이고 삭제 대상 노드의 레벨이 n라고 가정할 때, 1번 과정에서는 n번의 비교 연산이 필요하다. 2번 successor 노드를 찾기 위해서는 삭제 대상 노드의 서브트리 높이(h-d)에 해당하는 비교 연산을 수행해야 한다. 3번 4번은 복사하고 삭제하는 과정으로 상수시간이 걸려 무시할 만 하다. 종합적으로 따지면 O(d+h-d), 즉 O(h)가 된다.
노드가 루트의 한쪽으로 쏠려버리면 균형이 안맞아서 비효율적이다. 그러면 O(n)이 되는데 이를 해결하기 위해 균형을 맞추는 AVL Tree가 고안되었다.
AVL 트리는 편향된 트리의 균형을 맞추기 위한 트리이다.
이진 탐색 트리의 속성을 가진다.
왼쪽, 오른쪽 서브 트리의 높이 차이가 최대 1이다.
높이 차이가 1보다 커지면 회전(Rotation)을 통해 균형을 맞춰 높이 차이를 줄인다.
삽입, 검색, 삭제의 시간 복잡도가 O(log N)이다. (N : 노드의 개수)
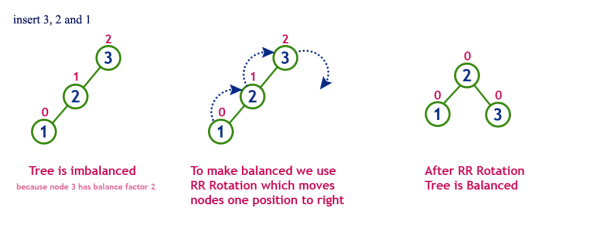
회전 과정에 대해 알아보기 전에 알아야 할 것이있다. AVL트리는 균형이 무너졌는지에 대해 판단할 때 Balance Factor라는 것을 활용한다. 이는 아래와 같은 공식으로 구한다.
BF(K) = K의 왼쪽 서브트리의 높이 - K의 오른쪽 서브트리의 높이
우회전
1. y노드의 오른쪽 자식 노드를 z노드로 변경한다.
2. z노드 왼쪽 자식 노드를 y노드의 오른쪽 서브트리(T2)로 변경한다.
좌회전
1. y노드의 왼쪽 자식 노드를 z노드로 변경한다.
2. z노드 오른쪽 자식노드를 y노드의 왼쪽 서브트리(T2)로 변경한다.
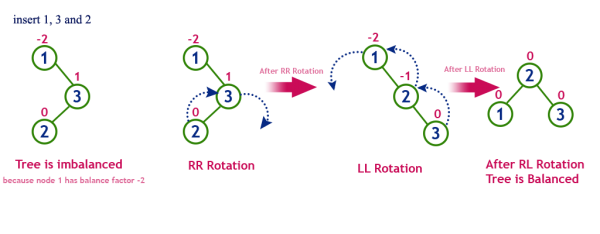
Case를 기준으로 트리의 균형을 맞춘다.
LL Case일 때 해당 노드 기준 우회전
RR Case일 때 해당 노드 기준 좌회전
LR Case왼쪽 자식노드 기준으로 좌회전 히고 해당 노드 기준 우회전
RL Case오른쪽 자식노드 기준으로 우회전 하고 해당 노드 기준 좌회전
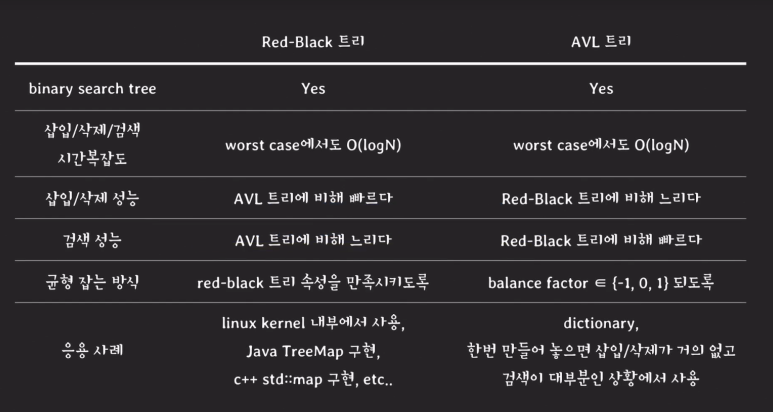
AVL트리는 이진 탐색트리의 균형을 맞출 뿐, 삽입 삭제는 비효율적이기 때문에, Dictionary 같은 잘 변동이 없는 것을 구현할 때 주로 사용되고, 삽입 삭제를 효율적으로 하기 위해 고안된 트리가 바로 RB트리이다.