
참고한 데이터 : https://www.blockchain.com/ko/charts/market-price?timespan=60days
Blockchain.com | Charts - Unknown Chart
The most trusted source for data on the bitcoin blockchain.
www.blockchain.com
위의 데이터를 가져온다.
.index: DataFrame 또는 Series에서 인덱스를 참조한다. 데이터 구조의 행에 접근하는 데 사용된다.
.set_index(keys): DataFrame에서 특정 열을 인덱스로 설정하다. keys에 지정된 열이 새로운 인덱스로 사용된다.
head(n=5): DataFrame 또는 Series의 처음 n행을 반환한다. n을 지정하지 않으면 기본적으로 처음 5행을 보여준다.
.describe() 함수는 pandas DataFrame 또는 Series의 기술 통계량을 요약하여 보여준다. 기본적으로 수치형 데이터에 대한 요약 통계량을 반환하며, 이에는 평균(mean), 표준편차(std), 최솟값(min), 최댓값(max), 사분위수(25%, 50%, 75%) 등이 포함된다.
문자열이나 카테고리형 데이터가 포함된 경우, .describe(include=['object', 'category'])와 같이 include 매개변수를 사용해 요약 정보를 얻을 수 있다. 이 경우, 유니크한 값의 개수(count), 가장 흔한 값(top), 그 값이 나타나는 빈도(freq) 등의 정보를 포함한다.
plot() 함수는 데이터 시각화 라이브러리인 Matplotlib에서 데이터를 그래프로 그리기 위해 사용된다. plt.show()는 그려진 그래프를 화면에 표시하다. 예를 들어, X축과 Y축 데이터 간의 관계를 선 그래프로 나타내고자 할 때 plot() 함수를 사용하고, 최종적으로 그래프를 보기 위해 plt.show()를 호출한다.
ARIMA 모델은 시계열 데이터를 분석하고 예측하기 위한 통계적 방법이다. ARIMA는 AutoRegressive Integrated Moving Average의 약자로, 세 가지 주요 구성 요소로 이루어져 있다.
- 자기 회귀(AR: AutoRegressive): 모델이 이전 관측값의 의존성을 설명한다. 파라미터 p는 과거 관측값이 현재 값을 예측하는 데 사용되는 시차의 수를 나타낸다.
- 차분(I: Integrated): 비정상성을 제거하기 위해 원 시계열 데이터에 차분을 적용하는 과정을 말한다. 파라미터 d는 데이터가 정상성을 달성하기 위해 필요한 차분의 횟수를 나타낸다.
- 이동 평균(MA: Moving Average): 모델이 이전 예측 오차의 의존성을 설명한다. 파라미터 q는 과거 예측 오차가 현재 값을 예측하는 데 사용되는 시차의 수를 나타낸다.
Prophet 모델은 Facebook에서 개발한 시계열 예측을 위한 도구다. 주로 일일 활동 패턴, 주간 및 연간 계절성 등이 명확한 시계열 데이터에 대한 예측에 적합하다. Prophet은 특히 휴일 효과나 이벤트가 예측에 중요한 역할을 하는 경우에 유용하며, 누락 데이터나 이상치가 있는 데이터셋에서도 견고한 예측 성능을 보인다.
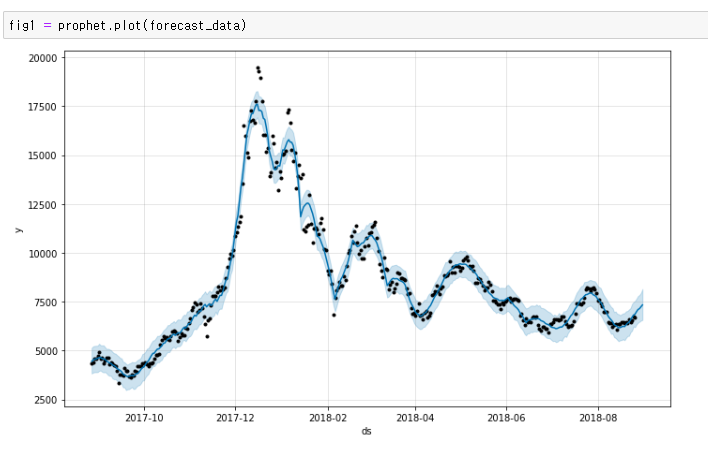
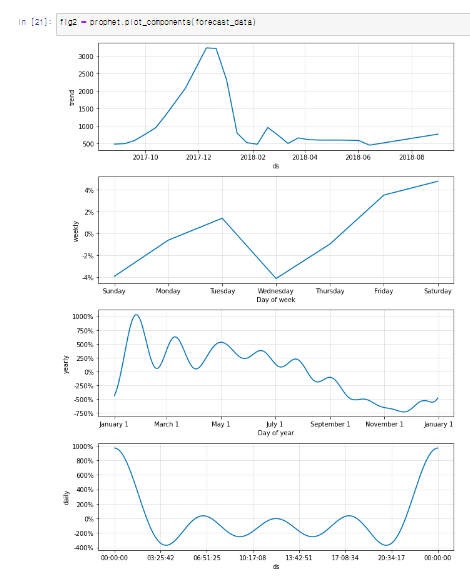
위 사진 2개가 prohet 모델이며 페이스북에서 라이브러리를 오픈하여 그걸 이용한 모델이다. 간편한편 이며 직관적인 api를 제공하며 유연성과 확장성이 높은 모델이다. 대신 외생 변수를 직접적을 처리하기 어렵고 과거 데이터의 의존하는 경향이 있다.
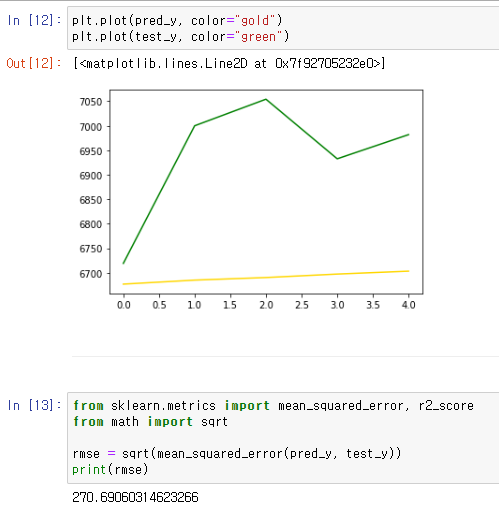
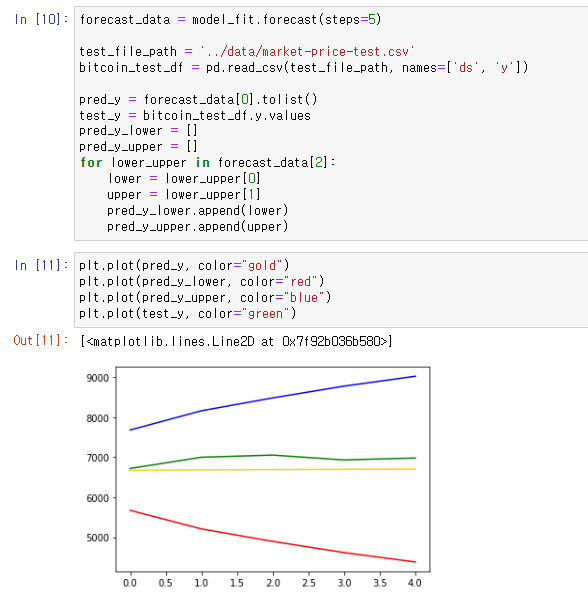
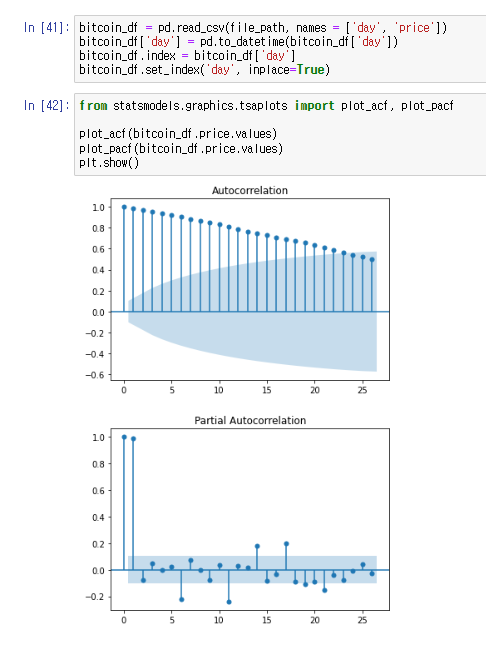
위쪽 2장의 사진은 arima 모델을 사용한것이고 제일 아래쪽 사진이 statsmodel 모델을 사용한것 이다.
ARIMA는 시계열 데이터 분석에 사용되는 모델이며 ARIMA 모델은 데이터의 자기 상관성과 추세를 모델링하여 미래 값을 예측하는데 사용된다.
이 모델은 적절한 파라미터 조정과 데이터 전처리를 통해 높은 예측 정확도를 제공하며 계절성이나 추세 등의 시계열 패턴을 캡처하는 데 유용하다.
대신 단기예측에 적합해서 장기적인 예측은 제한적이며 경제 지표나 기상정보등 외생변수를 처리하기 어려운 부분이 있다.
statsmodels는 많은 종류의 통계 모델 피팅, 통계 테스트 수행, 데이터 탐색과 시각화를 위한 라이브러리이다. 이 모델은 통계 분석에 특화가 된 모델이며 가설감정 및 추론을 위한 다양한 감정 기능을 제공한다. 대신 데이터 전처리 기능이 제한적이며 시각화를 위한 기능이 제한적이다.
다양한 모델을 이용한 시각화 그래프를 다루고 사용해 봤는데 가장 실제값과 예측값이 잘맞은것은 prophet 모델을 이용한 시각화 그래프 였다.
prophet모델은 연간, 월간, 주간, 일간 등의 주기적 변화를 모델링한다. Fourier series를 사용해 복잡한 계절성 패턴을 유연하게 캡처할 수 있다. 또한, 공휴일이나 특별 이벤트 등 예측 대상 시계열 데이터에 영향을 미치는 날짜를 모델링한다. 사용자가 직접 휴일과 이벤트 날짜를 지정할 수 있다.
'데이터 > 데이터 예측' 카테고리의 다른 글
| Pandas, GoogleColab, LSTM을 이용한 코인 예측 예제 (0) | 2024.03.22 |
|---|







