가상 페이지라고도 불리는 “페이지”는, 4,096 바이트(페이지 크기)의 길이를 가지는 가상 메모리의 연속된 영역이다. 페이지는 반드시 페이지에 정렬(page-aligned)되어 있어야 한다. 즉, 각 페이지는 페이지 크기(4KiB)로 균등하게 나누어지는 가상 주소에서 시작해야 한다는 말이다.
그러므로 64비트 가상주소의 마지막 12비트는 페이지 오프셋(또는 그냥 “오프셋”)이다. 상위 비트들은 페이지 테이블의 인덱스를 표시하기 위해 쓰인다. 64비트 시스템은 4단계 페이지 테이블을 사용하는데, 아래 그림과 같은 가상주소를 만들어준다.
63 48 47 39 38 30 29 21 20 12 11 0
+-------------+----------------+----------------+----------------+-------------+------------+
| Sign Extend | Page-Map | Page-Directory | Page-directory | Page-Table | Page |
| | Level-4 Offset | Pointer | Offset | Offset | Offset |
+-------------+----------------+----------------+----------------+-------------+------------+
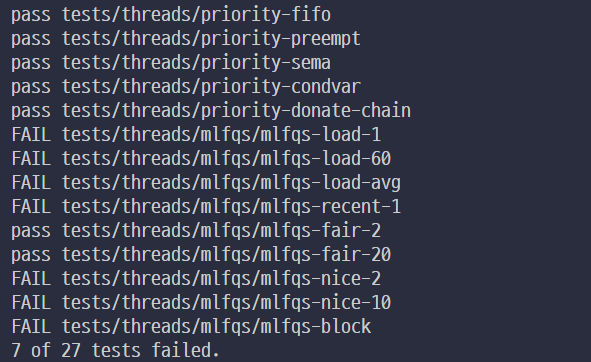
| | | | | |
+------- 9 ------+------- 9 ------+------- 9 ------+----- 9 -----+---- 12 ----+
Virtual Address
각 프로세스는 KERN_BASE (0x8004000000) 미만의 가상주소값을 가지는 독립적인 유저(가상)페이지 집합을 가진다. 반면에 커널(가상)페이지 집합은 전역적이며, 어떤 쓰레드나 프로세스가 실행되고 있든 간에 항상 같은 위치에 남아 있다. 커널은 유저 페이지와 커널 페이지 모두에 접근할 수 있지만, 유저 프로세스는 본인의 유저 페이지에만 접근할 수 있다.
물리 프레임 또는 페이지 프레임이라고도 불리는 프레임은, 물리 메모리 상의 연속적인 영역이다. 페이지와 동일하게, 프레임은 페이지사이즈여야 하고 페이지 크기에 정렬되어 있어야 한다. 그러므로 64비트 물리주소는 프레임 넘버와 프레임 오프셋(또는 그냥 오프셋)으로 나누어질 수 있다. 아래 그림처럼 말이다.
12 11 0
+-----------------------+-----------+
| Frame Number | Offset |
+-----------------------+-----------+
Physical Address
x86-64 시스템은 물리주소에 있는 메모리에 직접적으로 접근하는 방법을 제공하지 않는다. Pintos는 커널 가상 메모리를 물리 메모리에 직접 매핑하는 방식을 통해서 이 문제를 해결한다 - 커널 가상메모리의 첫 페이지는 물리메모리의 첫 프레임에 매핑되어 있고, 두번째 페이지는 두번째 프레임에 매핑되어 있고, 그 이후도 이와 같은 방법으로 매핑되어 있다. 그러므로 커널 가상메모리를 통하면 프레임들에 접근할 수 있다.
페이지 테이블은 CPU가 가상주소를 물리주소로, 즉 페이지를 프레임으로 변환하기 위해 사용하는 자료구조이다. 페이지 테이블 포맷은 x86-64 아키텍쳐에 의해 결정되었다. Pintos는 threads/mmu.c안에 페이지 테이블을 관리하는 코드를 제공한다.
아래 도표는 페이지와 프레임 사이의 관계를 나타낸다. 왼쪽에 보이는 가상주소는 페이지 넘버와 오프셋을 포함하고 있다. 페이지 테이블은 페이지 넘버를 프레임 넘버로 변환하며, 프레임 넘버는 오른쪽에 보이는 것처럼 물리주소를 획득하기 위한 미수정된 오프셋과 결합되어 있다.
+----------+
.--------------->|Page Table|-----------.
/ +----------+ |
| 12 11 0 V 12 11 0
+---------+----+ +---------+----+
| Page Nr | Ofs| |Frame Nr | Ofs|
+---------+----+ +---------+----+
Virt Addr | Phys Addr ^
\_______________________________________/
스왑 슬롯은 스왑 파티션 내의 디스크 공간에 있는 페이지 크기의 영역이다. 하드웨어적 제한들로 인해 배치가 강제되는 것(정렬)이 프레임에서보단 슬롯에서 더 유연한 편이지만, 정렬한다고 해서 별다른 부정적인 영향이 생기는 건 아니기 때문에 스왑 슬롯은 페이지 크기에 정렬하는 것이 좋다.
각 자료구조에서 각각의 원소가 어떤 정보를 담을지를 정해야 했었다. 또한 자료구조의 범위를 지역(프로세스별)으로 할지, 전역(전체 시스템에 적용)으로 할지도 정해야 하고, 해당 범위에 필요한 인스턴스의 수도 결정해야 한다. 설계를 단순화하기 위해, non-pageable 메모리 (calloc 이나 malloc 에 의해 할당된)에 이러한 자료구조들을 저장할 수 있다.
userprog/process.c에 있는 load_segment와 lazy_load_segment를 구현해야 했다. 실행파일로부터 세그먼트가 로드되는 것을 구현하고, 구현된 모든 페이지들은 지연적으로 로드될 것이다. 즉 이 페이지들에 발생한 page fault를 커널이 다루게 된다는 의미이다.
program loader의 핵심인 userprog/process.c 의 load_segment loop 내부를 수정해야 했다. 루프를 돌 때마다 load_segment는 대기 중인 페이지 오브젝트를 생성하는vm_alloc_page_with_initializer를 호출한다. Page Fault가 발생하는 순간은 Segment가 실제로 파일에서 로드될 때 이다.
static bool
load_segment(struct file *file, off_t ofs, uint8_t *upage,
uint32_t read_bytes, uint32_t zero_bytes, bool writable)
{
ASSERT((read_bytes + zero_bytes) % PGSIZE == 0);
ASSERT(pg_ofs(upage) == 0);
ASSERT(ofs % PGSIZE == 0);
while (read_bytes > 0 || zero_bytes > 0)
{
/* Do calculate how to fill this page.
* We will read PAGE_READ_BYTES bytes from FILE
* and zero the final PAGE_ZERO_BYTES bytes. */
size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE;
size_t page_zero_bytes = PGSIZE - page_read_bytes;
/* TODO: Set up aux to pass information to the lazy_load_segment. */
struct lazy *aux = (struct lazy*)malloc(sizeof(struct lazy));
aux->file = file;
aux->ofs = ofs;
aux->read_bytes = page_read_bytes;
aux->zero_bytes = page_zero_bytes;
if (!vm_alloc_page_with_initializer (VM_ANON, upage,
writable, lazy_load_segment, aux)){
return false;
}
/* Advance. */
read_bytes -= page_read_bytes;
zero_bytes -= page_zero_bytes;
upage += PGSIZE;
ofs += page_read_bytes;
}
return true;
}
VM 시스템은 mmap 영역에서 페이지를 lazy load하고 mmap된 파일 자체를 매핑을 위한 백업 저장소로 사용해야 한다. 이 두 시스템 콜을 구현하려면 vm/file.c에 정의된 do_mmap과 do_munmap을 구현해서 사용해야 한다.
fd로 열린 파일의 오프셋(offset) 바이트부터 length 바이트 만큼을 프로세스의 가상주소공간의 주소 addr 에 매핑 한다.
전체 파일은 addr에서 시작하는 연속 가상 페이지에 매핑된다. 파일 길이(length)가 PGSIZE의 배수가 아닌 경우 최종 매핑된 페이지의 일부 바이트가 파일 끝을 넘어 "stick out"된다. page_fault가 발생하면 이 바이트를 0으로 설정하고 페이지를 디스크에 다시 쓸 때 버린다.
성공하면 이 함수는 파일이 매핑된 가상 주소를 반환한다. 실패하면 파일을 매핑하는 데 유효한 주소가 아닌 NULL을 반환해야 한다.
void *
do_mmap (void *addr, size_t length, int writable,
struct file *file, off_t offset) {
struct file* new_file = file_reopen(file);
if(new_file == NULL){
return NULL;
}
void* return_address = addr;
size_t read_bytes;
if (file_length(new_file) < length){
read_bytes = file_length(new_file);
} else {
read_bytes = length;
}
size_t zero_bytes = PGSIZE - (read_bytes%PGSIZE);
ASSERT (pg_ofs (addr) == 0);
ASSERT (offset % PGSIZE == 0);
ASSERT ((read_bytes + zero_bytes) % PGSIZE == 0);
while (read_bytes > 0 || zero_bytes > 0) {
/* Do calculate how to fill this page.
* We will read PAGE_READ_BYTES bytes from FILE
* and zero the final PAGE_ZERO_BYTES bytes. */
size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE;
size_t page_zero_bytes = PGSIZE - page_read_bytes;
struct lazy* file_lazy = (struct lazy*)malloc(sizeof(struct lazy));
file_lazy->file = new_file;
file_lazy->ofs = offset;
file_lazy->read_bytes = page_read_bytes;
file_lazy->zero_bytes = page_zero_bytes;
if (!vm_alloc_page_with_initializer(VM_FILE, addr, writable, lazy_load_segment, file_lazy)){
return NULL;
}
/* Advance. */
read_bytes -= page_read_bytes;
zero_bytes -= page_zero_bytes;
addr += PGSIZE;
offset += page_read_bytes;
}
return return_address;
}
지정된 주소 범위 addr에 대한 매핑을 해제한다.
지정된 주소는 아직 매핑 해제되지 않은 동일한 프로세서의 mmap에 대한 이전 호출에서 반환된 가상 주소여야 한다.
void
do_munmap (void *addr) {
struct supplemental_page_table *spt = &thread_current()->spt;
struct page *page = spt_find_page(spt, addr);
int page_count;
if (file_length(&page->file)%PGSIZE != 0){
page_count = file_length(&page->file) + PGSIZE;
} else {
page_count = file_length(&page->file);
}
for (int i = 0; i < page_count/PGSIZE; i++)
{
if (page)
destroy(page);
addr += PGSIZE;
page = spt_find_page(spt, addr);
}
}
file-backed 페이지의 내용은 파일에서 가져오므로 mmap된 파일을 백업 저장소로 사용해야 한다. 즉, file-backed 페이지를 evict하면 해당 페이지가 매핑된 파일에 다시 기록된다.
파일에서 콘텐츠를 읽어 kva 페이지에서 swap in한다. 파일 시스템과 동기화해야 한다.
static bool
file_backed_swap_in (struct page *page, void *kva) {
struct file_page *file_page = &page->file;
struct lazy* aux = (struct lazy*)page->uninit.aux;
lock_acquire(&filesys_lock);
bool result = lazy_load_segment(page, aux);
lock_release(&filesys_lock);
return result;
}
내용을 다시 파일에 기록하여 swap out한다. 먼저 페이지가 dirty인지 확인하는 것이 좋다. 더럽지 않으면 파일의 내용을 수정할 필요가 없다. 페이지를 교체한 후에는 페이지의 더티 비트를 꺼야 한다.
static bool
file_backed_swap_out (struct page *page) {
struct file_page *file_page = &page->file;
struct lazy* aux = (struct lazy*)page->uninit.aux;
struct file * file = aux->file;
if(pml4_is_dirty(thread_current()->pml4,page->va)){
file_write_at(file,page->va, aux->read_bytes, aux->ofs);
file_write_at(file_page->file,page->va, file_page->read_bytes, file_page->ofs);
pml4_set_dirty(thread_current()->pml4, page->va, false);
}
page->frame->page = NULL;
page->frame = NULL;
pml4_clear_page(thread_current()->pml4, page->va);
return true;
}
https://github.com/yunsejin/PintOS_RE/tree/Project3_RE
GitHub - yunsejin/PintOS_RE: PintOS_Project1,2,3
PintOS_Project1,2,3. Contribute to yunsejin/PintOS_RE development by creating an account on GitHub.
github.com
'CS > 운영체제' 카테고리의 다른 글
| Pint OS_Project 2 구현 - 2(system call) (0) | 2024.04.01 |
|---|---|
| Pint OS_Project 2 구현 - 1(argument passing) (1) | 2024.03.29 |
| Page Replacement Policy (0) | 2024.03.27 |
| Demand-zero page, Anonymous page, File-backed page (0) | 2024.03.27 |
| 하이퍼바이저, 애뮬레이션, QEMU (0) | 2024.03.26 |