이번 포스팅에서 정의한 테이블 및 데이터:
CREATE DATABASE mydatabase;
CREATE USER 'myundb'@'localhost' IDENTIFIED BY 'password';
GRANT ALL PRIVILEGES ON mydatabase.* TO 'myundb'@'localhost';
FLUSH PRIVILEGES;
USE mydatabase;
CREATE TABLE user(
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(500) NOT NULL,
name VARCHAR(500) NOT NULL,
nickname VARCHAR(500) NOT NULL,
pw VARCHAR(500) NOT NULL,
newdate DATETIME DEFAULT CURRENT_TIMESTAMP,
updatedate DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
CONSTRAINT user_pk PRIMARY KEY (id)
);
예시 데이터 집어넣기:

MySQL 데이터베이스에 저장된 데이터를 확인하는 방법은 여러 가지가 있다.
첫 번째 방법은, 명령 프롬프트 또는 터미널에서 MySQL 클라이언트를 시작하고
mysql -u your_username -p
사용할 데이터베이스를 선택한다.
USE your_database_name;
그리고 필요한 데이터를 조회한다. 예를 들어, users 테이블의 모든 데이터를 조회하려면
SELECT * FROM users;이렇게 할 수 있다.
결과 화면:

두 번째 방법은 MySQL Workbench에서 확인하는 방법이다.
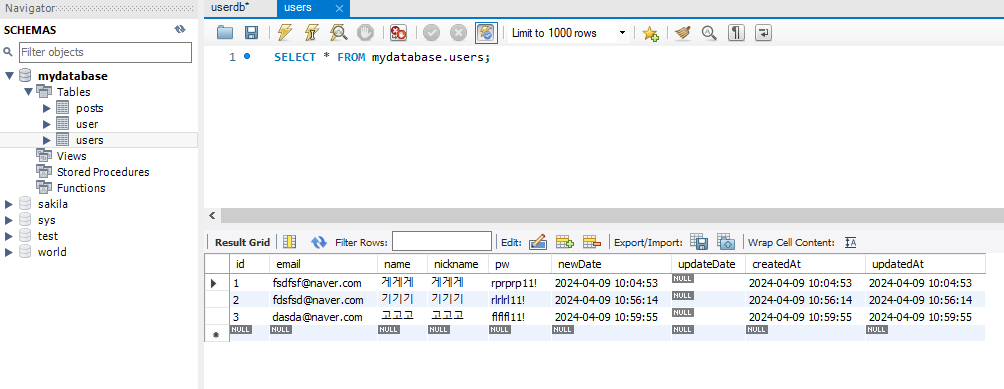
SELECT * FROM mydatabase.users; 를 쿼리로 실행해도 되고, UI로도 가능하다.
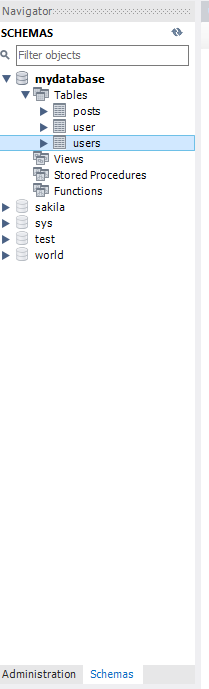
스키마에서 조회하고자 하는 테이블을 우클릭하고 Select Rows - Limit 1000을 누르면 상위 1000개의 데이터 목록을 확인할 수 있다. 만약 테이블을 정의해도 Schema에 데이터베이스가 안뜨면, Schemas 부분에 우클릭을 한 뒤, Load Spatial Data를 눌러 최근 리스트들을 갱신해야 한다.
결과 화면:
MySQL 데이터 베이스 관리 도구인 phpMyAdmin을 사용하여 브라우저를 통해 데이터베이스에 접속하고, 테이블을 조회하거나 SQL 쿼리를 실행할 수도 있다.
phpMyAdmin
Your download should start soon, if not please click here. Please verify the downloaded file Please take additional steps to verify that the file you have downloaded is not corrupted, you can verify it using the following methods: phpMyAdmin needs your con
www.phpmyadmin.net
'데이터 > SQL' 카테고리의 다른 글
| MySQL 테이블, user 정의 및 PATH 설정 (0) | 2024.04.08 |
|---|---|
| DB Index(SQL, NO SQL), Error Code: 1064 (0) | 2024.04.05 |