프로그래밍에서 함수나 메서드를 호출할 때 인자를 전달하는 방식에는 주로 Call by Value(값에 의한 호출)와 Call by Reference(참조에 의한 호출) 두 가지 방법이 있다. 이 두 전달 방식은 함수를 호출할 때 인자가 어떻게 함수에 전달되는지, 그리고 함수 내에서 인자의 값을 변경했을 때 그 변경이 호출자에게 반영되는지 여부에 대한 차이를 나타낸다.
call byvalue는 함수에 인자를 전달할 때, 인자의 실제 값을 복사하여 함수에 전달하는 방식이다. 함수 내에서 인자의 값을 변경해도, 원본 인자에는 영향을 미치지 않는다. 왜냐하면 함수에는 원본 인자의 복사본이 전달되기 때문이다. 주로 기본 자료형(정수, 실수, 문자 등)을 인자로 사용할 때 보이는 특성이다.
void addOne(int x) {
x = x + 1;
}
int main() {
int num = 10;
addOne(num);
// 여기서 num의 값은 여전히 10이다.
}
call by reference는 함수에 인자를 전달할 때, 인자의 메모리 주소를 전달하는 방식이다. 함수 내에서 인자의 값을 변경하면, 그 변경이 원본 인자에도 반영된다. 함수에는 원본 인자를 가리키는 주소가 전달되기 때문이다. 주로 복잡한 자료형(객체, 배열 등)을 인자로 사용할 때 보이는 특성이다.
void addOne(int& x) {
x = x + 1;
}
int main() {
int num = 10;
addOne(num);
// 여기서 num의 값은 11이 된다.
}
public void updateArray(int[] arr) {
arr[0] = 100;
}
public static void main(String[] args) {
int[] myArray = {1, 2, 3};
new Test().updateArray(myArray);
// 여기서 myArray[0]은 100이 된다.
}
Python에서 가비지 컬렉션은 메모리 관리의 한 형태로, 프로그램에서 더 이상 사용되지 않는 메모리를 자동으로 회수하는 프로세스를 말한다.
Python의 가비지 컬렉터는 주로 참조 카운팅(reference counting) 방식을 사용하여, 어떤 객체에 대한 참조가 더 이상 존재하지 않을 때 해당 객체를 메모리에서 해제한다. 추가적으로, 순환 참조(circular references)를 탐지하고 제거하기 위해 세대별(generational) 가비지 컬렉션을 사용한다.
Java에서 가비지 컬렉션은 JVM이 자동으로 메모리 관리를 수행하는 과정이다. 이 과정은 사용되지 않는 객체를 식별하고, 메모리에서 제거하여 애플리케이션의 효율성을 극대화한다. 가비지 컬렉션의 핵심 알고리즘에는 마킹 및 스위핑, 복사, 마킹-콤팩트, 그리고 세대별 수집이 포함된다.
메타 데이터는 데이터에 대한 데이터라는 의미를 가진다. Java에서는 클래스, 메서드, 변수 등과 같은 프로그램 요소에 대한 정보를 의미한다. 예를 들어, 클래스 파일(.class)에는 클래스 이름, 메서드 시그니처, 변수 타입 등 해당 클래스에 관한 정보가 메타 데이터로 포함된다.
메타 스페이스는 Java 8 이전에는 클래스 로더가 로드한 클래스 메타 데이터가 퍼머넌트 제너레이션(Permanent Generation, PermGen) 영역에 저장되었다. Java 8에서는 PermGen이 제거되고, 메타 스페이스라는 새로운 메모리 영역이 도입되었다. 메타 스페이스는 네이티브 메모리(non-heap memory)를 사용하여 클래스 메타 데이터를 저장한다.
PermGen 영역은 고정된 크기를 가지고 있었고, 이로 인해 많은 클래스를 로드하는 애플리케이션에서는 java.lang.OutOfMemoryError: PermGen space 오류가 발생할 수 있었다. 메타 스페이스는 필요에 따라 동적으로 확장될 수 있어 이러한 문제를 해결한다.
메타 스페이스는 JVM 외부의 네이티브 메모리를 사용하기 때문에, JVM의 힙 메모리 영역과 독립적으로 관리된다. 따라서 메타 데이터의 크기가 JVM의 최대 힙 크기에 영향을 미치지 않으며, 더 유연한 메모리 관리가 가능해진다.
메타 스페이스의 크기는 JVM 시작 시 -XX:MetaspaceSize와 -XX:MaxMetaspaceSize 옵션을 통해 초기 크기와 최대 크기를 설정할 수 있다. 이를 통해 애플리케이션의 요구 사항에 맞게 메타 스페이스의 메모리 사용을 조절할 수 있다.
HTTP 메소드는 클라이언트가 서버에게 수행하길 원하는 동작을 지정하는 데 사용된다. 주로 웹에서 자원(resource)에 대한 CRUD(Create, Read, Update, Delete) 작업을 수행할 때 사용된다.
GET 메소드는 지정된 리소스를 검색하여 요청에 응답한다. 웹 페이지나 이미지와 같은 자원을 조회할 때 사용된다. 데이터를 조회하는 데 사용되므로, 서버의 데이터나 상태를 변경하지 않는다(idempotent). URL에 쿼리 문자열(query string)을 포함시켜 데이터를 서버로 전송할 수 있다.
POST 메소드는 요청된 자원을 서버에 제출하여 생성하거나 업데이트한다. 폼(form) 데이터나 파일 업로드를 서버로 전송할 때 사용된다. 데이터를 서버로 전송할 때 사용되며, 서버의 상태나 데이터를 변경할 수 있다. 데이터는 HTTP 메시지의 바디(body)에 포함되어 전송된다.
PUT 메소드는 명시된 리소스를 요청 payload로 전송된 데이터로 생성하거나 업데이트한다. 지정된 리소스의 상태를 업데이트하거나, 지정된 URI에 리소스를 생성할 때 사용된다. 서버의 리소스를 지정된 데이터로 대체한다. 리소스가 없으면 새로 생성할 수 있다(idempotent).
DELETE 메소드는 지정된 리소스를 삭제한다. 서버의 특정 리소스를 삭제할 때 사용된다. 서버의 리소스를 삭제하는 데 사용되며, 삭제 성공 여부는 서버의 구현에 따라 다를 수 있다(idempotent).
이 외에도 HTTP/1.1 스펙에는 HEAD, OPTIONS, TRACE, CONNECT, PATCH 등의 다른 메서드도 정의되어 있다. PATCH는 리소스의 부분적인 수정을 위해 사용되며, 나머지 메서드들은 특별한 경우에 사용되는 보조적인 메서드들이다.
REST API (Representational State Transfer API)는 분산 시스템 설계를 위한 아키텍처 스타일 중 하나로, 웹 기술을 사용하여 애플리케이션 컴포넌트 간에 정보를 교환한다. REST는 HTTP 프로토콜의 기본 원칙을 활용하여 구현되며, 각 리소스(데이터 항목)에 고유한 URI를 할당하고, 표준 HTTP 메서드(GET, POST, PUT, DELETE 등)를 사용하여 리소스에 대한 CRUD(Create, Read, Update, Delete) 작업을 수행한다.
REST API는 상태를 유지하지 않는(stateless) 통신을 지향하기 때문에, 각 요청은 독립적이며 요청 간에 클라이언트의 상태 정보가 서버에 저장되지 않는다. 이는 서버 설계를 단순화시키고, 확장성을 높이는 데 도움이 된다. REST API는 웹 서비스, 모바일 애플리케이션 백엔드, 클라우드 기반 서비스와 같은 다양한 분야에서 널리 사용된다.
DNS (Domain Name System)는 인터넷 상에서 도메인 이름(예: www.example.com)을 컴퓨터가 이해할 수 있는 IP 주소(예: 192.0.2.1)로 변환하는 분산형 데이터베이스 시스템이다. 사용자가 웹 브라우저에 도메인 이름을 입력하면, DNS 서버는 해당 도메인 이름에 해당하는 IP 주소를 조회하여 사용자의 요청을 올바른 서버로 안내한다. 이 과정은 사용자가 복잡한 IP 주소를 기억하지 않고도 웹 사이트에 쉽게 접근할 수 있게 해준다. DNS 시스템은 루트, TLD(Top-Level Domain), 그리고 권한 있는 네임 서버 등 여러 계층으로 구성되어 있다.
dns 서버 요청에 응답받음
HTTP 상태코드(Status Codes)는 서버가 클라이언트의 요청을 어떻게 처리했는지 나타낸다.
1xx (정보적): 요청을 받았으며 프로세스를 계속 진행한다.
2xx (성공): 요청이 성공적으로 수행됐다를 알린다. (예: 200 OK)
3xx (리다이렉션): 추가 작업이 요청을 완료하기 위해 필요하다.
4xx (클라이언트 오류): 클라이언트의 잘못된 요청. (예: 404 Not Found)
5xx (서버 오류): 서버가 요청을 수행할 수 없음. (예: 500 Internal Server Error)
MIME 타입(Multipurpose Internet Mail Extensions Type)은 문서, 파일, 바이트 스트림의 포맷을 설명하는 표준화된 방식이다. 원래는 이메일에서 다양한 형태의 콘텐츠를 전송하기 위해 개발되었지만, 이후 웹에서 파일 형식을 식별하는 데 널리 사용되기 시작했다. MIME 타입은 타입/서브타입 형태로 구성되며, 때때로 추가 매개변수를 포함할 수 있다.
MIME 타입의 예
텍스트 파일: text/plain, text/html, text/css, text/javascript
이미지 파일: image/jpeg, image/png, image/gif
오디오 파일: audio/mpeg, audio/ogg
비디오 파일: video/mp4, video/ogg
응용 프로그램 특정 파일: application/json, application/xml, application/pdf, application/zip
웹 서버는 정적 파일을 클라이언트(브라우저)에 전송할 때, HTTP 헤더의 일부로 적절한 MIME 타입을 포함시킨다. 이를 통해 브라우저는 받은 콘텐츠를 어떻게 처리할지 결정할 수 있다. 예를 들어, text/html은 HTML 문서로, image/png는 PNG 이미지로 처리한다.
웹 브라우저는 MIME 타입을 이용하여 다운로드할 파일을 어떻게 표시하거나 처리할지 결정한다. 예를 들어, 일부 MIME 타입은 브라우저 내에서 직접 표시할 수 있으며(예: 텍스트, 이미지), 다른 타입은 추가 소프트웨어나 플러그인이 필요할 수 있다.
또한, MIME 타입은 이메일의 본문과 첨부 파일에 대한 정보를 제공한다. 이를 통해 이메일 클라이언트는 텍스트, HTML, 이미지 등 다양한 포맷의 콘텐츠를 적절하게 표시할 수 있다.
JPG(JPEG), PNG, 그리고 GIF는 디지털 이미지를 저장하기 위해 널리 사용되는 이미지 파일 포맷이다. 각 포맷은 특정 용도와 환경에 맞게 최적화되어 있으며, 이미지의 품질, 파일 크기, 지원 기능 등에서 차이를 보인다.
JPG(JPEG(Joint Photographic Experts Group))는 손실 압축 방식을 사용하여 파일 크기를 줄인다. 이 때문에 원본 이미지에서 일부 데이터를 잃게 되지만, 인간의 눈으로 구별하기 어려운 수준으로 조정할 수 있다. 고품질의 사진이나 그림과 같은 복잡한 이미지에 적합하다. 압축률을 조정할 수 있어, 사용자는 이미지의 품질과 파일 크기 사이의 균형을 선택할 수 있다.
PNG(Portable Network Graphics)는 손실 없는 압축을 제공하여, 이미지의 모든 디테일을 보존한다. 투명도(알파 채널)를 지원하여, 이미지의 일부분을 투명하게 할 수 있다. 이는 웹 디자인에서 로고나 아이콘 등을 배치할 때 유용하다. GIF에 비해 더 많은 색상(24비트 색상)을 지원한다.
GIF(Graphics Interchange Format)는 256색만 지원하는 제한된 색상 팔레트를 가지고 있어, 단순한 그래픽이나 애니메이션에 적합하다. 애니메이션 기능을 지원한다. 여러 이미지(프레임)를 한 파일에 저장하여 움직이는 이미지를 만들 수 있다. 손실 없는 압축을 사용하지만, 색상의 제한으로 인해 복잡한 이미지에는 적합하지 않다.
JPG를 PNG 형식으로, JPG를 PNG 형식으로 등 확장자를 변환해주는 사이트도 있다.
메모리 할당 방식에는 여러 가지가 있으며, 그 중 implicit(암시적), explicit(명시적), segregated list(분리된 리스트)는 메모리 블록을 관리하는 데 사용되는 대표적인 방법들이다. 각 방식은 메모리를 할당하고 해제하는 방법, 그리고 가용 메모리 블록을 추적하는 방법에서 차이를 보인다.
Fist Fit은 사용 가능한 메모리 블록 리스트를 처음부터 탐색해 요청된 크기를 수용할 수 있는 첫 번째 블록을 할당한다. 탐색 과정이 단순하며 때로 빠르다. 하지만 메모리 앞부분에 작은 블록들이 많이 남게 되어 큰 메모리 요청을 처리할 때 효율이 떨어질 수 있다. 이는 외부 단편화로 이어진다.
Next Fit은 Last Fit과 유사하되, 마지막으로 메모리를 할당한 위치부터 탐색을 시작해 전체 리스트를 순환한다. 마지막 할당 위치에서 시작하기 때문에 전체 메모리 공간의 사용이 더 균일해질 수 있다. 하지만 탐색 효율성이 낮아질 수 있으며, 큰 블록 요청 시 외부 단편화 문제가 발생할 수 있다.
Best Fit은 요청된 크기를 수용할 수 있으면서 가장 작은 블록을 선택해 할당한다. 메모리 낭비를 최소화하여 외부 단편화의 가능성을 줄인다. 하지만 전체 리스트를 탐색해야 하므로 탐색 시간이 길어질 수 있으며, 빈번한 작은 블록 할당으로 인해 내부 단편화가 발생할 수 있다.
implicit(암시적) 메모리 할당 방식은 free list를 사용하여 가용 메모리 블록을 추적한다. 이 리스트는 메모리 내의 가용 블록들을 순차적으로 연결한다. 메모리 할당 요청이 들어오면, 할당자는 리스트를 처음부터 탐색하여, 요청된 크기를 수용할 수 있는 첫 번째 블록을 할당한다. 이 과정을 "first-fit" 탐색이라고도 한다.
이 포스팅에는 implicit을 더 효율적인 next-fit으로 변형한 코드만 다루고 있다.
mm_init 함수는 메모리 관리 시스템을 초기화하는 데 사용된다. 이 함수는 동적 메모리 할당자를 초기화하고, 필요한 초기 메모리 구조를 설정하여 사용자가 요청하는 메모리 할당 및 해제 요청을 처리할 준비를 한다.
int mm_init(void)
{
if ((heap_listp = mem_sbrk(4 * WSIZE)) == (void *)-1) // 초기 힙 메모리를 할당
return -1;
PUT(heap_listp, 0); // 힙의 시작 부분에 0을 저장하여 패딩으로 사용
PUT(heap_listp + (1 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 블럭의 헤더에 할당된 상태로 표시하기 위해 사이즈와 할당 비트를 설정하여 값을 저장
PUT(heap_listp + (2 * WSIZE), PACK(DSIZE, 1)); // 프롤로그 블록의 풋터에도 마찬가지로 사이즈와 할당 비트를 설정하여 값을 저장
PUT(heap_listp + (3 * WSIZE), PACK(0, 1)); // 에필로그 블록의 헤더를 설정하여 힙의 끝을 나타내는 데 사용
heap_listp += (2 * WSIZE); // 프롤로그 블록 다음의 첫 번째 바이트를 가리키도록 포인터 조정
find_nextp = heap_listp; // nextfit을 위한 변수
if (extend_heap(CHUNKSIZE / WSIZE) == NULL) // 초기 힙을 확장하여 충분한 양의 메모리가 사용 가능하도록 chunksize를 단어 단위로 변환하여 힙 확장
return -1;
if (extend_heap(4) == NULL) //자주 사용되는 작은 블럭이 잘 처리되어 점수가 오름
return -1;
return 0;
}
mm_malloc 함수의 구현은 메모리 관리 시스템의 일부로, 요청된 크기의 메모리 블록을 동적으로 할당하는 기능을 제공한다. 이 함수는 요청된 크기를 조정하여 오버헤드와 정렬 요구 사항을 충족시키고, 적절한 크기의 블록을 찾거나 힙을 확장하여 메모리를 할당한다.
void *mm_malloc(size_t size)
{
size_t asize; /* Adjusted block size */
size_t extendsize; /* Amount to extend heap if no fit */
char *bp;
/* Ignore spurious requests */
if (size == 0)
return NULL;
/* Adjust block size to include overhead and alignment reqs. */
if (size <= DSIZE)
asize = 2 * DSIZE;
else
asize = DSIZE * ((size + (DSIZE) + (DSIZE - 1)) / DSIZE);
/* Search the free list for a fit */
if ((bp = find_fit(asize)) != NULL)
{
place(bp, asize);
return bp;
}
/* No fit found. Get more memory and place the block */
extendsize = MAX(asize, CHUNKSIZE);
if ((bp = extend_heap(extendsize / WSIZE)) == NULL)
return NULL;
place(bp, asize);
return bp;
}
아래는 동적 메모리 할당기의 일부로 사용되는 find_fit 함수의 구현 예시이며, "Next Fit" 메모리 할당 전략을 사용한다. 이 함수의 목적은 요청된 크기(asize) 이상의 가용 메모리 블록을 찾는 것이다.
static void *find_fit(size_t asize)
{
/* Next-fit search */
void *bp;
bp = find_nextp;
// 현재 블록이 에필로그 블록이 아닌 동안 계속 순회, 블록의 헤더 크기가 0보다 크지 않으면 에필로그 블럭
for (; GET_SIZE(HDRP(find_nextp)) > 0; find_nextp = NEXT_BLKP(find_nextp))
{
// 가용 블럭의 헤더가 할당되어 있지 않고 요청된 크기보다 크거나 같은 경우 해당 가용 블록을 반환
if (!GET_ALLOC(HDRP(find_nextp)) && (asize <= GET_SIZE(HDRP(find_nextp))))
{
return find_nextp;
}
}
// 위의 for루프에서 가용 블럭을 찾지 못한 경우, 다시 순회
for (find_nextp = heap_listp; find_nextp != bp; find_nextp = NEXT_BLKP(find_nextp))
{ // 이전에 탐색했던 find_nextp 위치에서부터 다시 가용 블록을 찾아서 반환
if (!GET_ALLOC(HDRP(find_nextp)) && (asize <= GET_SIZE(HDRP(find_nextp))))
{
return find_nextp;
}
}
return NULL;
}
place 함수는 메모리 할당 과정에서 효율성을 높이기 위해 설계되었다. 할당 요청에 따라 메모리 블록을 최적으로 사용할 수 있도록 하며, 할당 후 남은 공간이 충분히 크면 이를 다시 가용 블록으로 반환하여 메모리 낭비를 줄인다. 이 과정은 메모리 단편화를 방지하고 메모리 사용 효율을 높이는 데 중요하다.
static void place(void *bp, size_t asize)
{
size_t csize = GET_SIZE(HDRP(bp)); // 현재 블록의 크기를 알아냄
// 남은 공간이 충분히 클 경우, 즉 요청한 크기(asize)와 현재 크기(csize)의 차이가
// 두 배의 더블 사이즈(DSIZE)보다 크거나 같으면 블록을 나눔
if ((csize - asize) >= (2 * DSIZE))
{
PUT(HDRP(bp), PACK(asize, 1)); // 사용할 블록의 헤더에 크기와 할당된 상태 저장
PUT(FTRP(bp), PACK(asize, 1)); // 사용할 블록의 푸터에도 똑같이 저장
bp = NEXT_BLKP(bp); // 나머지 블록으로 포인터 이동
PUT(HDRP(bp), PACK(csize - asize, 0)); // 나머지 블록의 헤더에 크기와 빈 상태 저장
PUT(FTRP(bp), PACK(csize - asize, 0)); // 나머지 블록의 푸터에도 똑같이 저장
}
else // 남은 공간이 충분히 크지 않으면 현재 블록 전체 사용
{
PUT(HDRP(bp), PACK(csize, 1)); // 현재 블록의 헤더에 크기와 할당된 상태 저장
PUT(FTRP(bp), PACK(csize, 1)); // 현재 블록의 푸터에도 똑같이 저장
}
}
coalesce 함수는 메모리 해제 또는 메모리 할당 과정 중에 인접한 가용 블록들을 하나의 큰 블록으로 합치는 역할을 한다. 이 과정은 메모리 단편화를 줄이고, 효율적인 메모리 사용을 가능하게 한다. 병합 방식은 주변 블록들의 할당 상태에 따라 달라진다.
realloc 함수는 주어진 포인터 ptr에 할당된 메모리 블록의 크기를 변경하기 위해 사용된다. 요청된 새 크기(size)에 따라 메모리 블록을 확장하거나 축소한다. 이 과정에서 필요하다면, 새로운 메모리 위치로 데이터를 복사하고 원래 메모리를 해제한다.
void *mm_realloc(void *ptr, size_t size)
{
void *oldptr = ptr;
void *newptr;
size_t copySize;
// 새로운 메모리 블록 할당
newptr = mm_malloc(size);
if (newptr == NULL)
return NULL;
// 이전 블록의 데이터 크기를 가져옴
copySize = GET_SIZE(HDRP(oldptr));
// 실제 복사할 데이터 크기는 이전 블록 크기와 요청된 새 블록 크기 중 작은 값
if (size < copySize)
copySize = size;
// 데이터를 새 블록으로 복사
memcpy(newptr, oldptr, copySize);
// 이전 블록 해제
mm_free(oldptr);
return newptr;
}
implicit 리스트를 사용한 메모리 할당에서는 가용 블록을 찾기 위해 리스트의 시작부터 순차적으로 탐색해야 한다. 큰 메모리 풀에서 적합한 블록을 찾는 데 시간이 오래 걸릴 수 있으며, 이는 메모리 할당과 해제 작업의 효율성을 떨어뜨린다. 메 모리 할당과 해제가 빈번하게 이루어질 경우, 암시적 방식은 빠르게 메모리 단편화를 야기하고, 이는 시간이 지남에 따라 전반적인 시스템 성능에 부정적인 영향을 미칠 수 있다.
위 구현된 implicit 외의 explicit(명시적) 메모리 할당 방식에서는 가용 메모리 블록을 관리하기 위해 별도의 자료 구조(예: 이중 연결 리스트)를 사용한다. 각 가용 블록은 다음과 이전의 가용 블록을 가리키는 포인터를 포함한다. 이를 통해 할당과 해제가 훨씬 유연하게 이루어질 수 있다.
segregated list(분리된 리스트) 메모리 할당 방식에서는 다양한 크기 범위에 따라 여러 개의 가용 리스트를 유지한다. 각 리스트는 특정 크기 범위의 블록들만을 포함한다. 메모리 할당 요청이 들어오면, 해당 크기 범위에 맞는 리스트를 선택하여 가용 블록을 탐색한다.
buddy system은 가변 크기의 메모리 할당을 지원하며, 특히 시스템 프로그래밍이나 운영 체제에서 자주 사용된다. Buddy System의 핵심 아이디어는 메모리를 고정된 크기의 블록으로 분할하고, 이 블록들을 필요에 따라 합치거나 분할하여 메모리를 할당하는 것이다. 이 과정에서 각 메모리 블록의 "buddy" 또는 짝을 이용해 효율적으로 메모리를 관리한다.
buddy system의 메모리는 2의 거듭제곱 크기의 블록으로 분할된다. 예를 들어, 메모리 크기가 2^N인 경우, 가능한 블록 크기는 2^0, 2^1, 2^2, ..., 2^N까지 다양하다. 그리고 할당을 할 때에는 요청된 메모리 크기에 가장 잘 맞는 블록 크기를 찾는다. 이는 요청 크기보다 크거나 같은 가장 작은 2의 거듭제곱 크기의 블록을 의미한다. 만약 해당 크기의 블록이 없다면, 더 큰 블록을 분할하여 요구를 충족시킨다.
각 블록은 고유한 buddy 또는 짝을 가지며, 이는 같은 크기의 인접한 블록을 의미한다. Buddy는 블록의 주소와 크기를 이용하여 계산할 수 있다. 메모리 블록이 해제될 때, 해당 블록의 buddy가 현재 사용 가능한지 확인한다. 만약 buddy도 사용 가능하다면, 두 블록을 합쳐서 더 큰 블록을 만든다. 이 과정을 반복하여 가능한 한 큰 블록을 유지한다.
UDP(User Datagram Protocol)는 연결이 없는 프로토콜로, 데이터 전송이 빠르지만 신뢰성은 낮다. 실시간 비디오 스트리밍, 온라인 게임 같은 상황에서 적합하다. TCP와 달리 1:1 or 1:n or n:m 통신이 가능하다.
UDP는 소켓 대신 IP를 기반으로 데이터를 전송하고, 데이터그램 단위로 전송되며, 그 크기는 65535바이트로, 크기가 초과하면 잘라서 보낸다. 흐름제어가 없어서 패킷이 제대로 전송되었는지, 오류가 없는지 확인할 수 없다. CheckSum 필드를 통해 최소한의 오류만 검출한다.
TCP/IP(Transmission Control Protocol/Internet Protocol)는 연결 지향적이며 데이터 전송이 신뢰성 있고 순서대로 이루어진다. 예를 들어, 웹 페이지 로딩, 이메일 전송 같은 작업에 사용된다. UDP와 달리 1:1 통신만 가능하다.
TCP/IP는 패킷 교환 방식과 전이중(Full-Duplex)과 점대점(Point to Point) 방식을 사용한다. 그리고 3-way handshaking을 통해 연결하고, 4-way handshaking을 통해 연결을 해제한다.
3-way handshaking:
3-way handshake는 두 장치 간에 안정적인 연결을 설정하는 데 사용되는 프로세스다. 데이터를 전송하기 전에 양쪽이 통신할 준비가 되었는지 확인한다.
SYN(Sychronize): 연결을 시작하는 장치는 SYN 플래그가 설정된 패킷을 보낸다. 이 패킷에는 장치가 보내는 데이터 패킷의 순서를 추적하는 데 사용할 시퀀스 번호가 포함된다.
SYN-ACK(Synchronize Acknowledge): 수신 장치는 SYN 및 ACK 플래그가 설정된 패킷으로 응답한다. ACK 플래그는 수신된 SYN 패킷을 확인하고 자체 시퀀스 번호를 포함한다.
ACK(Acknowledge): 연결을 시작하는 장치는 수신된 SYN-ACK 패킷을 확인하는 ACK 플래그가 설정된 최종 패킷을 보낸다.
4-way handshaking:
4-way handshake는 연결을 종료하기 전에 양쪽이 데이터 전송을 완료했는지 확인한다.
FIN(Finish): 한 장치는 더 이상 데이터를 보낼 수 없음을 나타내는 FIN 플래그가 설정된 패킷을 보낸다.
ACK(Acknowledge): 다른 장치는 ACK패킷으로 FIN패킷을 확인한다.
FIN(Finish): 수신 장치는 자체 FIN패킷을 보내 더 이상 데이터를 보낼 수 없음을 나타낸다.
ACK(Acknowledge): 연결을 시작하는 장치는 수신된 FIN 패킷을 ACK 패킷으로 확인한다.
패킷의 전송 과정은 이렇다.
응용 계층: 브라우저는 HTTP 요청 메시지를 생성한다.
전송 계층: TCP 프로토콜은 HTTP 요청 메시지를 헤더와 데이터로 분할하고, 각 부분을 패킷에 담아 전송한다.
네트워크 계층: IP 프로토콜은 각 패킷에 목적지 IP 주소를 추가하고, 라우팅 테이블을 참고하여 최적의 경로를 선택하여 전송한다.
데이터 링크 계층: MAC 주소를 기반으로 패킷을 목적지 장치로 전송한다.
물리 계층: 전기 신호 또는 광 신호로 변환하여 전송한다.
패킷의 헤더 정보는 송신지 IP 주소, 목적지 IP주소, 프로토콜, 포트 번호, 데이터 길이, 체크섬이 있다.
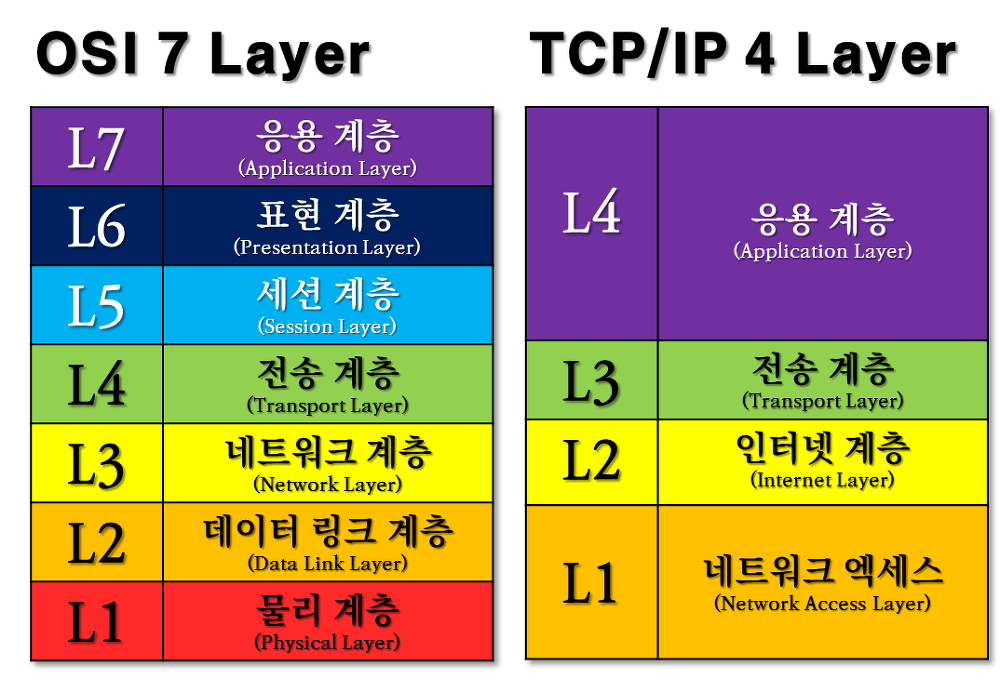
OSI 7 계층은 네트워크 통신에 있어서 표준화된 모델이다.
물리 계층(Physical Layer): 실제 전기적 신호를 전송하는 계층이다. 케이블, RJ45 등이 여기에 해당한다. 여기에 속하는 리피터, 허브에는 NIC, 고유 MAC 주소가 없다.
데이터 링크 계층(Data Link Layer): 네트워크 장비 간의 데이터 전송을 담당하며, MAC 주소를 사용한다. 이더넷, 스위치, Wi-Fi 등이 여기에 속한다.
네트워크 계층(Network Layer): 다른 네트워크 간의 데이터 전송을 관리하며, IP 주소를 사용한다. 라우터, IP, ARP가 여기에 해당한다.
전송 계층(Transport Layer): 두 장치 간의 데이터 전송을 책임지며, 신뢰성 있는 데이터 전송을 보장한다. TCP, UDP가 이 계층에 속한다.
세션 계층(Session Layer): 통신 장치 간의 세션을 관리한다. 세션 생성, 유지, 종료 등의 기능을 담당한다.
표현 계층(Presentation Layer): 데이터 표현 방식을 관리하며, 암호화와 압축을 담당한다. 예를 들어, ASCII, JPEG, MPEG 등의 데이터 형식이 여기에 해당한다.
응용 계층(Application Layer): 최종 사용자와 가장 가까운 계층으로, 사용자의 응용 프로그램이 네트워크 서비스를 사용할 수 있게 한다. HTTP, FTP, SMTP, DNS 등이 여기에 속한다.
NIC(Network Interface Controller)는 데스크탑이나 노트북에 RJ-45를 연결할 수 있는 포트와 연결된 하드웨어 장치이다.네트워크 어댑터, 이더넷 카드 등으로도 불리며, NIC에는 컴퓨터를 식별할 수 있는 고유 MAC주소가 있다. 이 MAC 주소는 제조업체에서 설정되며, 사용자가 변경할 수 없다. MAC 주소는 48비트 길이의 고유한 식별자로, 일반적으로 16진수로 표현된다. 예를 들어, 00:1A:2B:3C:4D:5E과 같은 형식이다.
NIC
이더넷(Ethernet)은 컴퓨터 네트워크 기술의 하나로, 전 세계적으로 가장 많이 사용되는 LAN(Local Area Network)기술이다. 이더넷은 최대 100Gbps 이상의 빠른 속도로 데이터를 전송할 수 있으며, 오류 감지 및 수정 기능을 통해 안정적인 데이터 전송을 제공한다. 이더넷은 다양한 케이블과 장비를 사용하여 확장할 수 있고, 다양한 제조업체의 장비가 서로 호환된다.
CSMA/CD는 네트워크에서 충돌을 감지하고 처리하는 방식 중 하나로, 이더넷과 같은 네트워크 환경에서 사용된다.
Carrier Sense (CS): 장비가 데이터를 전송하기 전에 먼저 물리적인 채널인 전송 매체(예: 케이블)을 감지한다. 이는 다른 장비가 이미 데이터를 전송 중이면 기다리는 것을 의미한다.
Multiple Access (MA): 다중 액세스는 여러 장비가 동시에 전송 매체에 액세스할 수 있는 능력을 말한다. 이는 네트워크에서 여러 장비가 동시에 데이터를 전송할 수 있어야 하는 상황에서 중요하다.
Collision Detection (CD): 충돌 감지는 데이터 전송 중에 충돌이 발생하는지 감지하고, 충돌이 발생하면 적절히 처리한다. 이는 두 개 이상의 장비가 동시에 데이터를 전송하여 데이터가 손상될 수 있는 상황에서 중요하다.
힙: 동적으로 할당되는 메모리 영역. 프로그래머가 직접 관리하며, 필요할 때 메모리를 할당하고 사용이 끝나면 해제한다. 힙은 메모리 할당과 해제가 자유롭기 때문에 스택보다 유연하지만, 메모리 누수나 단편화 같은 문제가 발생할 수 있다. 힙은 크기가 고정되어 있지 않고 프로그램 실행 동안 확장될 수 있다.
스택: 자동으로 할당 및 해제되는 메모리 영역. 함수 호출 시 생성되는 지역 변수와 함수 매개변수가 저장된다. 스택은 LIFO(Last In, First Out) 방식으로 작동한다. 함수가 호출되면 스택 프레임이 스택에 푸시되고, 함수가 종료되면 스택 프레임이 팝되어 메모리에서 제거된다. 스택은 크기가 고정되어 있으며, 스택 오버플로우가 발생할 수 있다.
주요 차이점:
스택은 컴파일러에 의해 자동으로 관리되며, 힙은 개발자가 직접 관리해야 한다.
스택은 정적/자동 할당이고, 힙은 동적 할당이다.
스택에 할당된 메모리는 함수 호출이 끝나면 자동으로 해제되지만, 힙에 할당된 메모리는 명시적으로 해제하지 않으면 프로그램 종료 시까지 남아 있다.
스택은 제한적인 반면, 힙은 더 크고 유연하다.
스택은 힙에 비해 더 빠른 할당과 해제가 가능하다.
코드 영역: 프로그램의 실행 가능한 기계어 코드가 저장되는 곳이다. 이 영역은 읽기 전용으로 설정되어 있어, 프로그램 실행 중에는 변경되지 않는다. 함수, 루프, 조건문 등의 실제 프로그램 코드가 여기에 위치한다.
데이터 영역: 프로그램의 전역 변수와 정적 변수(static variables)가 저장되는 영역이다. 이 영역에 저장되는 변수들은 프로그램의 생명 주기 동안 초기화된 값으로 유지되며, 프로그램 실행 도중에도 값이 변경될 수 있다. 데이터 영역은 두 부분으로 나뉘는데, 초기화된 데이터를 위한 영역과 초기화되지 않은 데이터를 위한 BSS 영역이 그것이다.
BSS 영역: 초기화되지 않은 전역 변수와 정적 변수가 저장되는 영역이다. BSS 영역에 있는 변수들은 프로그램이 시작할 때 0 또는 null 값으로 초기화된다. 이 영역의 목적은 메모리 사용을 최적화하기 위한 것으로, 실제로 프로그램에 필요한 메모리 공간만 할당하면서, 초기값이 필요 없는 변수들을 효율적으로 관리한다.
프로세스와 스레드는 메모리에 적재된다. 프로세스는 실행 중인 프로그램의 인스턴스로, 자신만의 메모리 공간(코드, 데이터, 힙, 스택 등)을 가진다. 스레드는 프로세스 내에서 실행되는 실행 단위로, 프로세스의 메모리 공간을 공유하지만 자신만의 스택을 가진다. 이를 통해 스레드 간의 데이터 공유와 통신이 용이하다.
프로세스간 통신(IPC, Inter-Process Communication)은 독립적인 프로세스들이 데이터를 주고받거나 동기화하는 방법이다.
파이프(Pipes): 단방향 통신 채널. 데이터는 한쪽 끝으로 들어가 다른 쪽으로 나온다.
명명된 파이프(Named Pipes): 이름을 가진 파이프로, 두 프로세스가 서로 다른 컴퓨터에 있어도 통신 가능.
메시지 큐(Message Queues): 메시지 기반의 통신 방식. 프로세스는 메시지 큐에 데이터를 쓰거나 읽음.
세마포어(Semaphores): 프로세스 동기화에 사용. 공유 자원에 대한 접근을 제어.
공유 메모리(Shared Memory): 프로세스들이 데이터를 공유하기 위해 메모리의 동일한 부분을 사용.
소켓(Sockets): 네트워크를 통한 프로세스 간 통신을 가능하게 함. 서버와 클라이언트 모델을 사용.
각 기법은 사용 상황과 요구 사항에 따라 선택된다. 예를 들어, 실시간 데이터 교환은 소켓이나 메시지 큐를 사용하며, 큰 데이터 블록의 공유는 공유 메모리가 적합하다. 동기화와 순서 보장이 중요할 때는 세마포어나 메시지 큐를 고려한다.
운영체제(Operating System, OS)는 컴퓨터 시스템의 핵심 소프트웨어다. 하드웨어와 응용 프로그램 간의 인터페이스 역할을 수행해 시스템의 자원을 효율적으로 관리하고 사용자에게 편리한 환경을 제공한다. 운영체제는 CPU와 메모리를 최대한 효율적으로 활용해 시스템의 성능을 극대화한다. 그리고 CPU 스케줄링 알고리즘을 사용해 다중 프로세스 및 스레드를 관리하고, 메모리 관리 기능을 통해 가상 메모리를 지원해 프로세스 간의 메모리를 분리하고 효율적으로 관리한다. 파일 시스템을 관리해 데이터를 저장하고 검색하는 데 필요한 기능을 제공한다.
또한 OS는 시스템의 하드웨어 자원을 관리한다. 이는 주변장치와의 통신을 조율하고, 장치 드라이버를 로드해 하드웨어를 제어하고 데이터를 전송하는 역할을 수행한다. 예를 들어, 네트워크 인터페이스 카드와의 통신을 위해 네트워크 스택을 제공하고, 프린터와의 통신을 위해 프린터 드라이버를 제공한다. 그리고 운영체제는 시스템의 보안을 유지하고 관리한다. 사용자 인증 및 권한 관리를 통해 시스템에 접근하는 사용자를 제어하고, 방화벽 및 바이러스 검사 프로그램을 통해 외부 위협으로부터 시스템을 보호한다.
운영체제는 하드웨어 측면에서 다양한 주변장치와의 통신을 관리하며, 이들 장치를 저속주변장치와 고속주변장치로 구분한다. 예를 들면, 키보드와 마우스는 데이터 전송 속도가 상대적으로 낮은 저속주변장치에 속하고, 그래픽 카드와 하드 디스크는 높은 데이터 전송 속도를 요구하는 고속주변장치에 속한다.
이러한 주변장치와의 통신 과정에서 버퍼의 역할은 매우 중요하다. 버퍼는 데이터를 일시적으로 저장하는 메모리 영역으로, 데이터의 전송 속도 차이를 완화하고 통신의 안정성을 높이는 데 기여한다. 예를 들어, 저속주변장치인 키보드에서 입력이 이루어지면, 입력 데이터는 우선 버퍼에 저장되고, 시스템이 처리할 준비가 되었을 때 CPU로 전달된다. 이 과정은 사용자의 입력 처리를 더욱 효율적으로 만든다.
반면, 고속주변장치인 하드 디스크와의 데이터 전송에서도 버퍼는 중요한 역할을 한다. 대량의 데이터를 빠르게 전송할 때, 버퍼는 주변장치와 CPU 사이의 속도 차이를 조절해 줌으로써 CPU가 다른 중요한 작업을 수행하는 동안 데이터를 안정적으로 전송받거나 보낼 수 있게 돕는다.
입출력 관련 기능에서 운영체제는 폴링 방식과 인터럽트 방식을 사용해 입출력을 관리한다. 폴링 방식은 CPU가 주변장치의 상태를 주기적으로 확인해 데이터를 전송하는 방식이다. 반면에 인터럽트 방식은 주변장치가 CPU에게 신호를 보내어 데이터를 전송하는 방식이다. 이를 통해 CPU의 부하를 줄이고 입출력 작업을 효율적으로 처리할 수 있다.
Direct Memory Access(DMA)는 컴퓨터 시스템에서 데이터 전송을 위한 메커니즘 중 하나로, CPU의 개입 없이 주변장치와 메모리 간의 데이터 전송을 처리하는 기술이다.
CPU는 데이터를 주변장치와 주고받을 때, CPU는 데이터를 주변장치에서 직접 읽어와 메모리에 쓰거나, 메모리에서 데이터를 읽어와 주변장치에 보내는 작업을 수행한다. 이러한 데이터 전송 과정에서 CPU는 각각의 데이터 전송을 직접 처리해야 하므로, CPU의 부하가 발생할 수 있다.
DMA는 이러한 문제를 해결하기 위해 도입된 기술로, 주변장치와 메모리 간의 데이터 전송을 CPU의 개입 없이 처리한다. DMA 컨트롤러는 CPU의 지시를 받아 데이터 전송 작업을 수행하고, 전송이 완료되면 CPU에 인터럽트를 발생시켜 CPU에게 전송 완료를 알린다.
DMA의 동작 과정
CPU는 DMA 컨트롤러에게 데이터 전송을 요청한다.
DMA 컨트롤러는 주변장치로부터 데이터를 읽거나, 메모리로부터 데이터를 읽어와서 주변장치로 전송한다.
데이터 전송이 완료되면 DMA 컨트롤러는 CPU에게 인터럽트를 발생시켜 전송 완료를 알린다.
DMA를 사용하면 CPU는 데이터 전송 작업을 처리하는 동안 다른 작업을 수행할 수 있으므로 시스템의 전반적인 성능이 향상된다. 또한, DMA를 사용하면 데이터 전송 속도도 향상되므로 대용량 데이터의 전송이 필요한 경우에 유용하게 사용된다.
주요 주변장치인 하드디스크나 네트워크 카드와 같은 고속 주변장치와의 데이터 전송에서 DMA가 널리 사용된다. 이러한 장치는 데이터를 빠르게 처리해야 하므로 CPU의 개입 없이 효율적으로 데이터를 전송할 수 있는 DMA가 필수적이다.
+ C의 stdio와 RIO 라이브러리
표준 입출력 라이브러리(stdio)와 RIO(Robust I/O) 라이브러리는 둘 다 입출력(I/O) 작업을 처리할 때 버퍼링을 사용하는 방식에 있어서 차이를 보인다. 이들은 프로그램이 데이터를 읽고 쓸 때 효율성과 안정성을 높이기 위해 버퍼를 사용한다.
stdio는 표준 C 라이브러리의 일부로, 파일이나 표준 입출력 등의 데이터 스트림을 처리할 때 버퍼링을 사용한다. 이는 데이터를 바로 읽거나 쓰지 않고, 일정량을 메모리에 임시로 저장한 후, 한 번에 처리하는 방식이다.
버퍼링은 입출력 효율을 높이고, 시스템 호출의 횟수를 줄여 성능을 향상시킨다. 예를 들어, 키보드로부터 입력을 받을 때마다 바로 처리하는 대신, 입력 데이터를 버퍼에 모아두었다가 한꺼번에 처리할 수 있다.
stdio에서는 전체 버퍼링(full buffering), 라인 버퍼링(line buffering), 노 버퍼링(no buffering) 등 세 가지 버퍼링 모드를 제공한다. 파일 I/O에서는 주로 전체 버퍼링이 사용되며, 터미널 I/O에서는 라인 버퍼링이 일반적이다.
RIO 라이브러리는 네트워크 프로그래밍에서 사용되는 비표준 I/O 라이브러리로, 불안정한 네트워크 환경에서도 안정적으로 데이터를 전송하기 위해 설계되었다. RIO는 내부적으로 버퍼링을 사용해 데이터를 처리한다.
RIO는 네트워크 입출력의 효율성과 안정성을 높이는 것을 목표로 한다. 특히, 네트워크를 통한 데이터 전송에서 발생할 수 있는 단편화와 같은 문제를 해결하기 위해 버퍼를 통해 데이터를 일정량 모은 후 전송한다.
RIO는 단순한 API를 제공하며, 입출력 작업 중에 발생할 수 있는 부분적인 읽기나 쓰기 문제(partial read/write)를 처리하기 위한 메커니즘을 포함한다. 예를 들어, 요청한 바이트 수만큼 정확히 읽거나 쓸 수 있도록 보장한다.
두 라이브러리 모두 버퍼링을 통해 입출력 작업의 효율성을 높인다. 데이터를 바로 전송하는 대신 버퍼에 모아서 처리함으로써 시스템 호출의 횟수를 줄이고 성능을 향상시킨다.
stdio는 일반적으로 파일 I/O와 표준 입출력에 사용되며, 데이터를 처리할 때 사용자가 버퍼링 모드를 선택할 수 있다. 반면, RIO는 네트워크 I/O에 특화되어 있으며, 내부적으로 버퍼링을 사용하여 데이터를 안정적으로 전송하는 데 초점을 맞춘다.