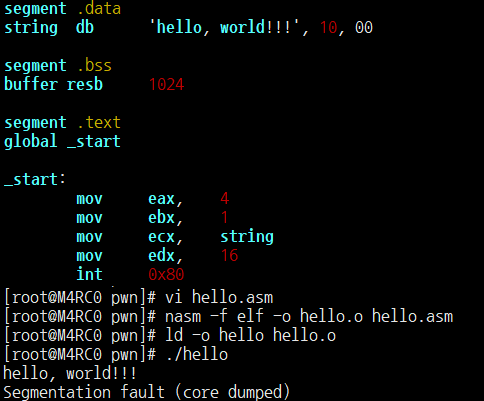
프로시저는 재사용 가능한 코드 블록이며, 함수와 유사하게 특정 작업을 수행한다. 프로시저 P에서 Q로의 호출 과정에는 몇 가지 필수 기능이 포함된다.
1. 제어권 전달: 프로그램 카운터(PC)는 진입할 때 Q에 대한 코드의 시작주소로 설정되고, 리턴할 때는 P에서 Q를 호출하는 인스트럭션 뒤로 설정되어야 할 것이다.
(Passing Control : PC는 Q의 코드의 시작 주소로 설정되고 Q를 호출한 후에 P의 명령어로 설정한다.)
2. 데이터 전달: P는 하나 이상의 매개변수를 Q에 제공할 수 있어야 하며, Q는 다시 Q로 하나 이상의 값을 리턴할 수 있어야 한다.
(Passing Data : P는 하나 이상의 파라미터를 Q에게 제공하고, Q는 P에게 값을 다시 반환한다.)
3. 메모리 할당과 반납: Q는 시작할 때 지역변수들을 위한 공간을 할당할 수 있고, 리턴할 때 이 저장소를 반납할 수 있다.
(Allocating and deallocating memory : Q는 지역 변수에 대한 공간을 할당할 필요가 있다.)
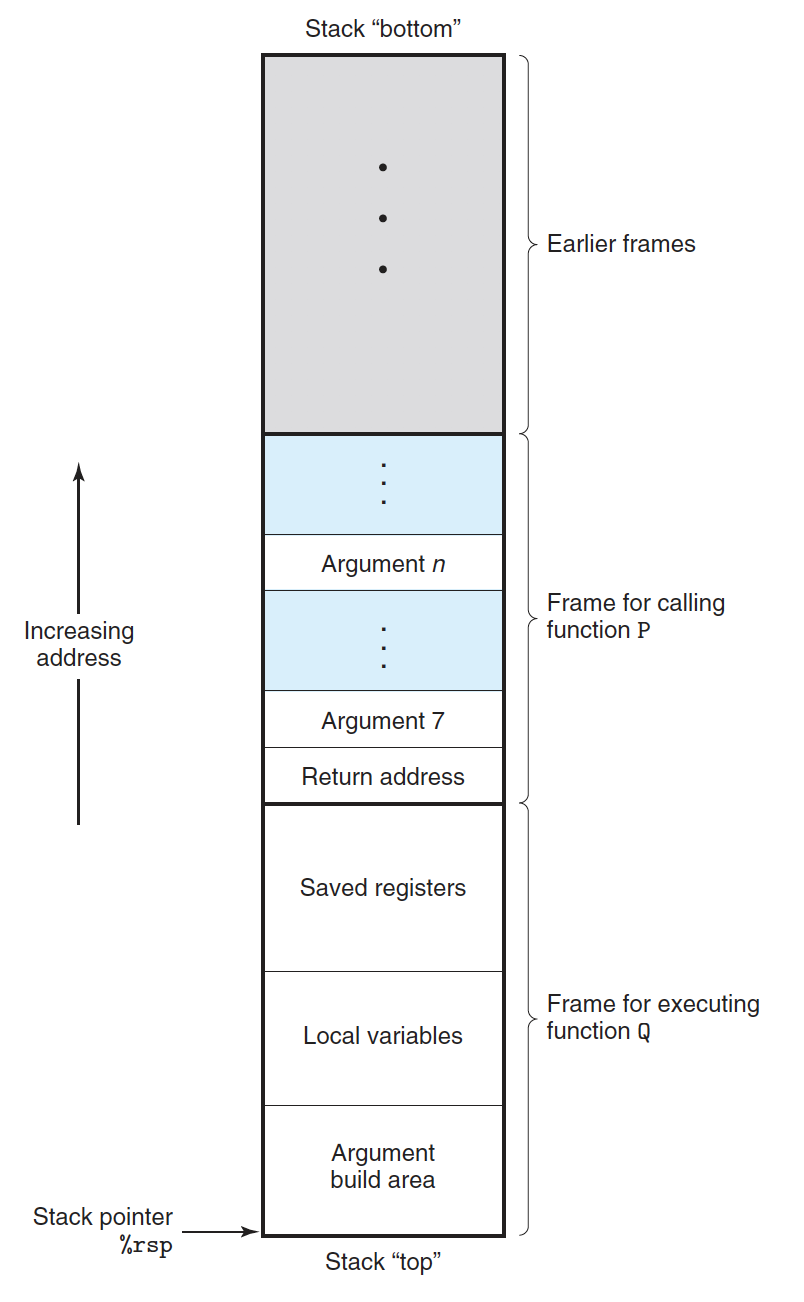
스택은 작은 주소 방향을 성장하며, 스택포인터 %rsp는 스택의 최상위 원소를 가리킨다.
x86-64 아키텍처에서 프로시저가 레지스터에 저장할 공간을 초과하면 스택에 데이터를 저장한다. 프로시저 호출은 스택의 LIFO 원칙을 따르며, 프로시저 Q가 실행 중일 때, 프로시저 P는 대기 상태에 들어간다. Q 실행 중에는 지역 변수를 위한 새로운 공간을 스택에 할당하고, 다른 프로시저 호출을 준비한다. Q가 끝나면 할당했던 로컬 저장소를 해제한다.
프로그램은 스택을 통해 프로시저가 요구하는 저장 공간을 관리한다. P가 Q를 호출하면, 제어와 데이터 정보가 스택에 추가되고, P로 돌아올 때 해당 정보는 스택에서 제거된다. P가 Q를 호출하면서 리턴 주소를 스택에 푸시한다. 이는 Q가 끝나고 P로 돌아가야 할 위치를 나타낸다. Q는 호출될 때 자신의 작업 공간을 스택에 할당하며, 이 공간 안에서 레지스터 값과 지역 변수를 위한 공간을 설정하고, 필요한 인자들을 준비한다
많은 함수는 스택 프레임을 요구하지 않고 주로 레지스터 내에서 처리한다. P는 최대 여섯 개의 정수 인자를 레지스터를 통해 전달할 수 있지만, Q가 더 많은 인자를 필요로 하면 P는 이들을 스택 프레임 안에 저장한다. 제어를 Q로 넘기는 것은 PC(Program Counter)를 Q의 시작 주소로 설정하는 것이다. Q가 끝나면, ret 명령어는 스택에서 리턴 주소를 팝하여 PC를 그 주소로 설정해 P로 돌아간다.
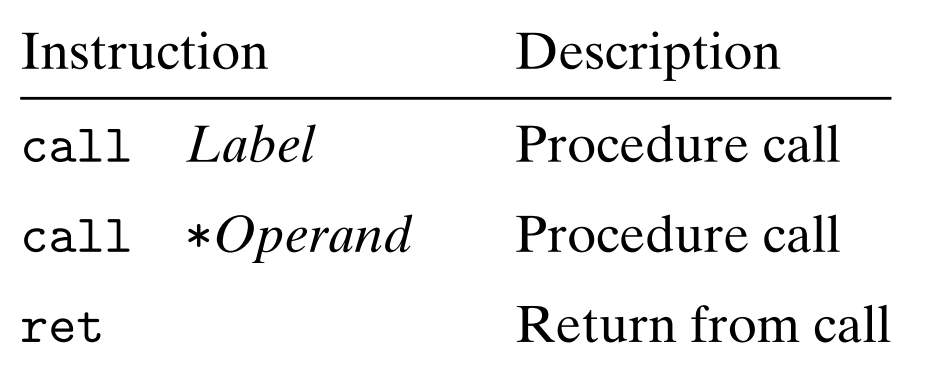
call 인스트럭션은 호출된 프로시저가 시작하는 주소를 목적지로 갖는다. jump 인스트럭션과 비슷하게 직접 호출할수도, *를 붙여 간접 호출할 수도 있다. (직접 호출은 라벨이 주어지는 반면에 간접 호출은 *로 주어진다.)
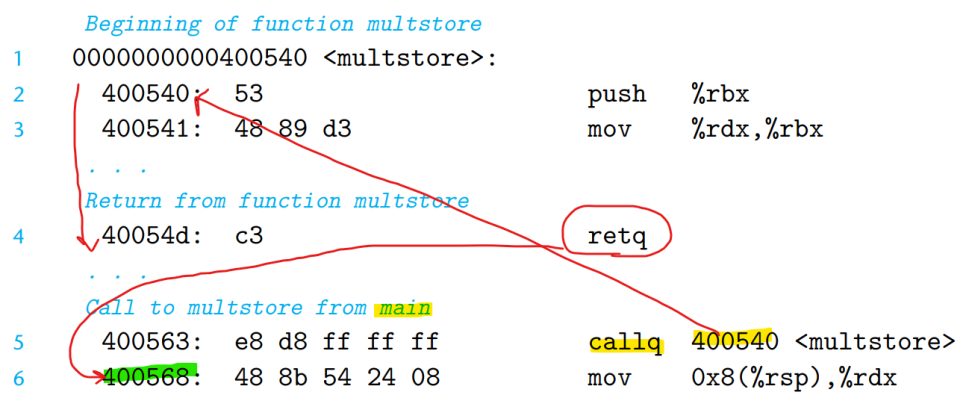
메인함수에서 call이 실행되면서 call 의 다음주소인 400568이 복귀주소로 스택에 푸시된다. 그런다음 쭉 내려와서 retq 가 실행되면, 다시 복귀주소를 팝하고 돌아온다.
제어를 함수 P에서 Q로 넘긴다는 것은 단순히 프로그램 카운터를 Q를 위한 코드 시작주소로 설정하는 것이면 된다. 그렇지만, 나중에 Q가 동작을 마치고 리턴해야 할 때가 오면 프로세서는 P의 실행을 다시 실행해야 하는 코드 위치의 일부 기록을 가지고 있어야 한다. 이를 담당하는 것이 call 인스트럭션이다.
함수 P에서 Q로 제어 전송을 하는 것은 PC에 Q 코드에 대한 시작 주소로 설정하면 된다.
나중에 Q가 반환할 시간이 오면, 프로세서는 P의 실행을 다시 재개해야 하는 위치를 기록해야 한다.
이 정보는 Q를 호출하는 명령어와 함께 프로시저 Q를 부르면서 x86-64 기계에 저장된다.
이 명령어는 스택에 주소 A를 푸시하고, PC를 Q의 시작 주소로 설정한다.
푸시된 주소는 반환 주소로 부르며 call 명령어로 명령어의 주소로써 계산된다.
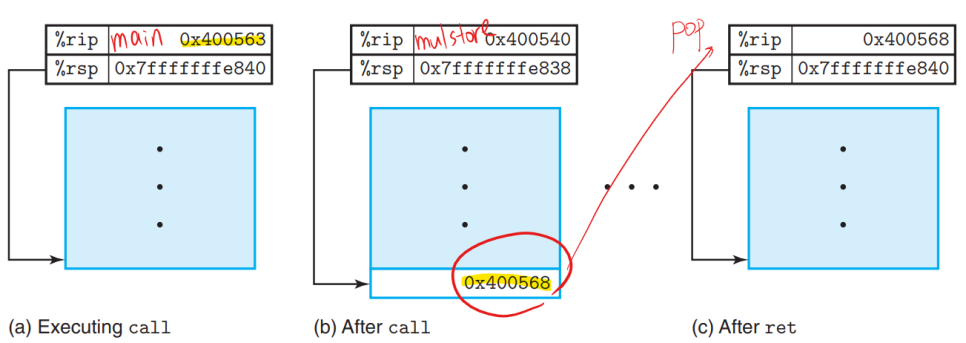
아래와 같이 조금 더 복잡한 경우도 살펴볼 수 있다. main함수 안에 top함수 안에 leaf함수가 있는 경우이다.
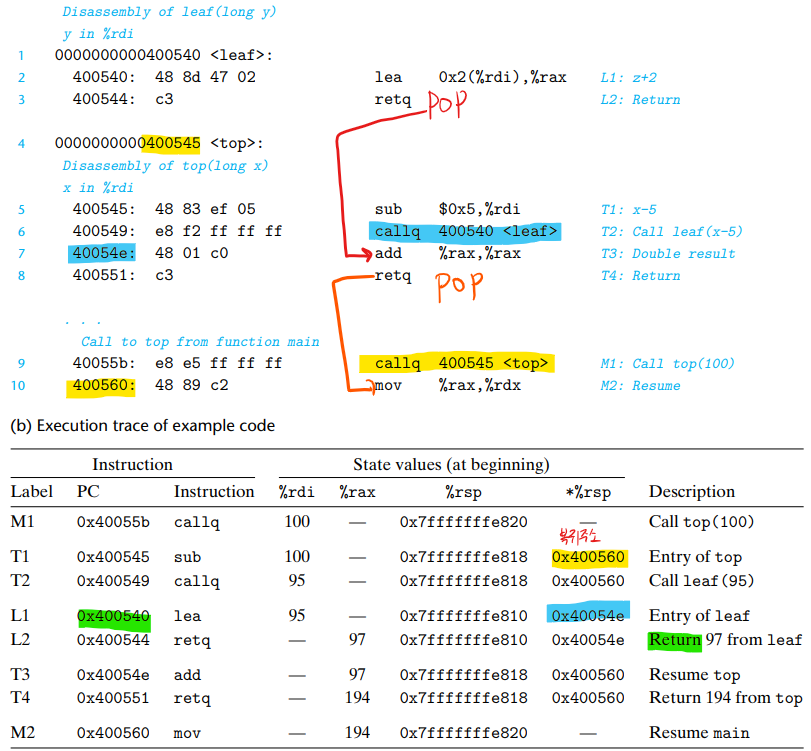
main함수가 실행되고 top함수가 호출되면 먼저 스택에는 main복귀주소가 들어가고 rip(PC)는 top으로 세팅된다. 그리고, top함수가 실행되면 그 안에있는 leaf함수도 실행된다. 이떄 top함수의 복귀주소가 들어가고, rip 는 leap로 세팅된다.
leap가 리턴되면 스택에서 팝한 것을 주소로하여 top으로 돌아온다.
top이 리턴되면 스택에서 팝한 값을 주소로 하여 main으로 돌아온다.
함수의 호출에 따라 %rsp의 이동, %rip의 이동, %rsp에는 어떤값이 푸시되는지, return할때는 retq에 의해 어떤 값이 팝되는지의 흐름을 이해해야 한다.
ret은 프로시저 호출이 끝날 때 사용되는 인스트럭션으로, 프로시저가 호출될 때 스택에 저장해 놓았던 복귀 주소를 읽어들여, 스택 프레임을 해제하고 해당 주소로 복귀한다.
x86-64에서는 최대 여섯개의 정수형 인자가 레지스터로 전달될 수 있다. 이 레지스터들은 전달되는 데이터 형의 길이에따라 레지스터 이름을 이용하여 정해진 순서로 이용된다. 인자들은 아래 리스트에서 각자의 순서에 따라 이들 레지스터에 할당된다. (64비트보다 작은 인자들은 더 작은 크기의 레지스터들로 할당 가능)
함수의 인자와 지역/전역변수를 포함한 데이터들의 이동을 고려하지 않고서는, 프로시저의 제어를 전달해봐야 아무 의미가 없다.
프로시저 P가 Q를 호출할때, P에대한 코드는 먼저 인자들을 적절한 레지스터들에 복사해야한다.
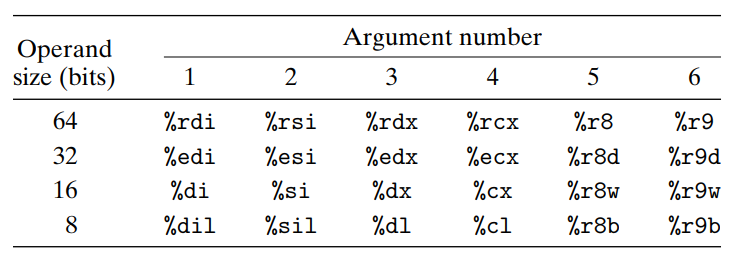
함수가 여섯개 이상의 정수형 인자를 가지면 6개를 넘어서는 인자들은 스택으로 전달된다.
인자7 에서 n까지를 위한 충분한 크기의 저장공간을 스택 프레임에 할당해야 한다.
다시말해 인자1~6은 적절한 레지스터들에 복사되고, 인자7~n까지는 스택탑에 넙는다.
Q는 레지스터와 스택을 통해 자신의 인자들에 접근할 수 있다.
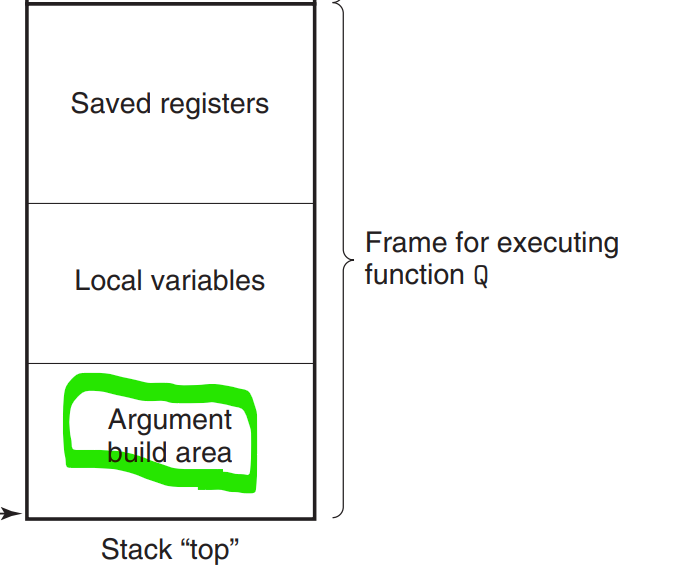
이후에 만약 Q가 여섯개가 넘는 인자를 갖는 어떤 함수를 호출하려면 앞에서 본 스택프레임에서 Argument build area라는 곳에 공간을 할당할 수 있다.
그렇다면 함수가 여섯 개 이상의 정수형 인자를 가진다면? 다른 인자들은 스택으로 전달된다. 인자 1~6은 적절한 레지스터에 복사하고, 인자 7에서 n까지는 인자 7을 스택 탑에 넣는 방법으로 저장한다.
호출된 프로시저에 제어를 넘겨주고 프로시저가 반환되면, 프로시저 호출은 인수 데이터를 넘기고, 프로시저로부터 반환되는 것은 값을 반환하는 것을 포함한다.
x86-64에서 6개의 인수가 레지스터를 통해 전달된다. 레지스터들은 전달된 데이터 타입의 크기에 맞는 레지스터를 위해 사용된 이름과 함께 구체적인 순서로 사용된다.
함수가 6개보다 많은 인수를 가지고 있으면, 다른 인수는 스택에 전달된다.
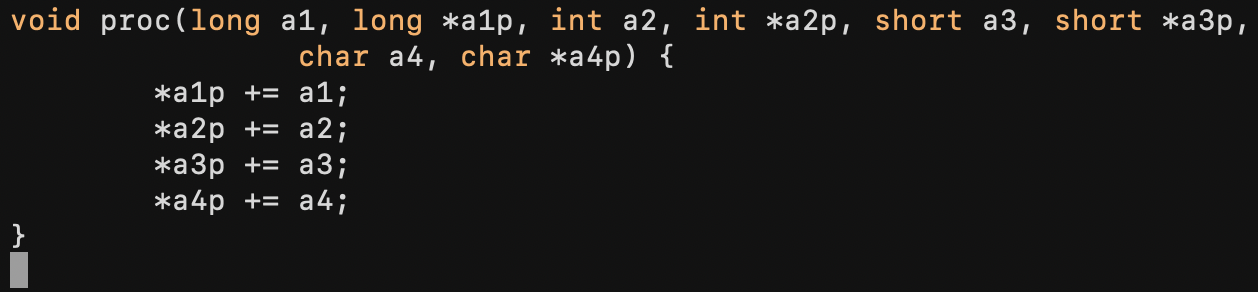
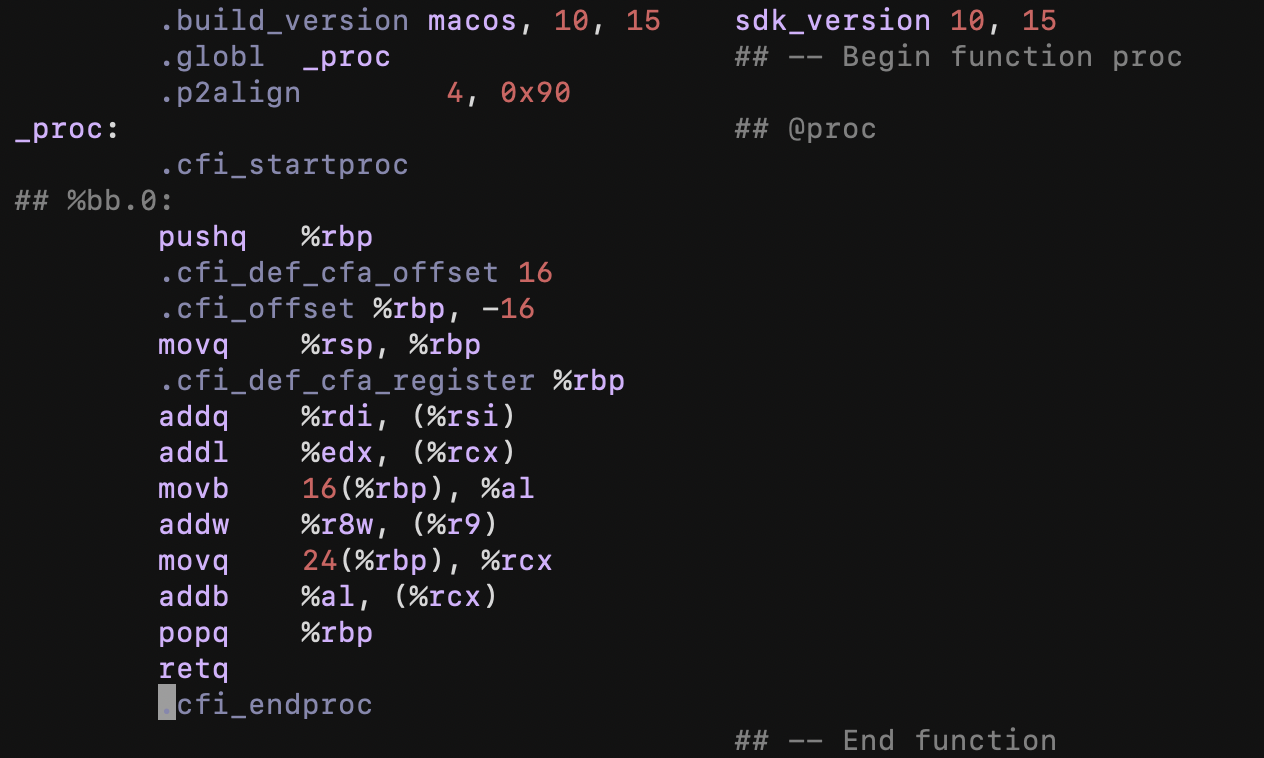
6번째 인수까지는 레지스터에 저장되지만 마지막 두 개는 스택으로 전달된다.
로컬 데이터는 메모리에 저장되어야 한다.
- 로컬 데이터를 가지고 있기에 충분한 레지스터가 없다.
- 주소 연산자 &는 지역 변수에 적용되어서 주소를 생성할 수 있어야 한다.
- 어떤 지역 변수는 배열이나 구조체이므로 배열이나 구조체 레퍼런스로 접근되어야만 한다.
일반적으로 프로시저는 스택 포인터를 감소시키면서 스택 프레임에 공간을 할당한다.
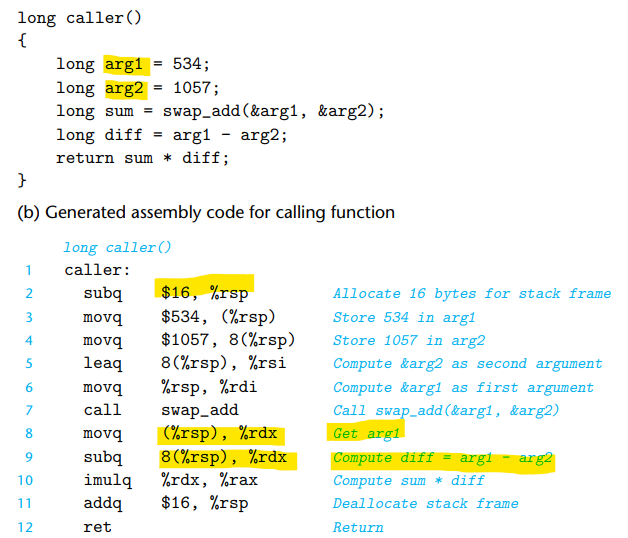
이 예에서는 함수가 지역 변수를 위해 스택을 사용하는 방식을 볼 수 있다. 함수 실행을 위해 스택을 16만큼 확장하고, movq 연산을 사용하여 함수 인자들을 스택에 배치한다. 함수가 실행된 후, 스택에서 지역 변수들을 사용하여 필요한 계산을 수행하고, 마지막에 스택 포인터를 원래 위치로 돌려 스택을 정리한다.
프로그램 레지스터는 모든 함수가 공유하는 자원으로, 한 함수가 다른 함수를 호출할 때, 호출된 함수(callee)는 호출하는 함수(caller)가 나중에 사용할 레지스터 값을 보존해야 한다. 이를 위해 callee는 callee-saved 레지스터(%rbx, %rbp, %r12-%r15)의 원래 값을 스택에 저장하고, 함수가 끝나기 전에 이 값을 복원해야 한다. 이 방식으로 레지스터 값을 안전하게 보존하며, 함수 간의 데이터 손실 없이 호출과 복귀가 이루어진다.
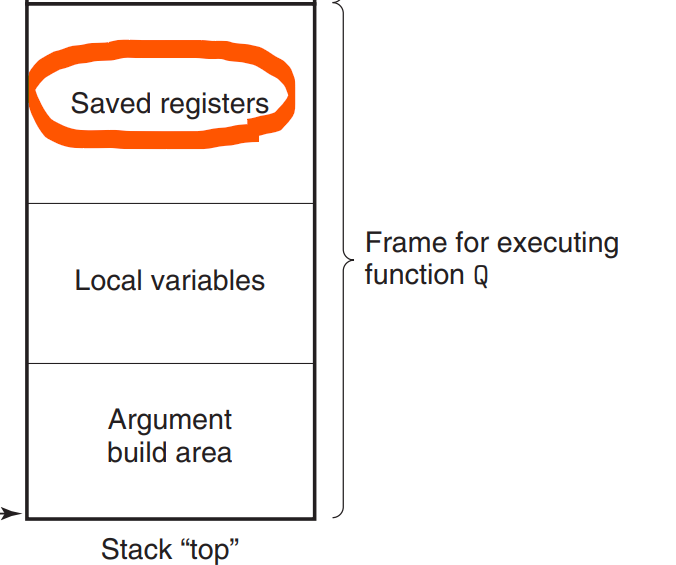
saved registers 자리에 값들이 저장됨으로써 P는 위에 정리한 Callee-saved-register들 또한 자유롭게 쓸 수 있다. Caller-saved-register은 결국에 %rsp를 뺀 나머지 모든 레지스터에 해당된다.

Saved registers 자리에 값들이 저장됨으로써 P는 위에 정리한 Callee-saved-register들 또한 자유롭게 쓸 수 있다. Caller-saved-register은 결국에 %rsp를 뺀 나머지 모든 레지스터에 해당된다.
재귀 프로시저도 마찬가지로 위에서 Caller - Callee의 관계처럼 진행된다.

함수 실행 시작에 %rbx 레지스터를 스택에 저장하는 것으로 시작한다. 실행이 끝나면, %rbx를 복원한다. 여기서 %rbx에 처음에 무엇이 저장되어 있었는지는 명시되지 않는다.
x86-64 프로시저 규칙은 함수가 재귀적으로 호출될 수 있도록 지원한다. 이는 각 함수가 스택에서 자신만의 공간을 가지고 있기 때문에 가능하다. 이로 인해 서로 다른 호출에서의 지역 변수들이 상호 간섭하지 않는다.
함수가 호출되었다가 반환될 때 스택에서 이루어지는 할당과 해제 작업은 로컬 저장소 관리를 위한 적절한 방법을 제공한다. 재귀 호출은 일반 함수 호출과 동일하게 처리되며, 스택의 할당 및 해제 규칙은 함수 호출의 순서와 일치한다.
'CS > 어셈블리어' 카테고리의 다른 글
| 어셈블리어와 제어문 (1) | 2024.03.21 |
|---|