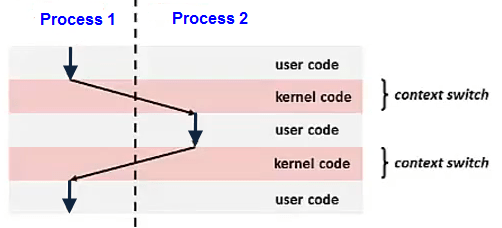
Pint OS의 Project 1이 구현되기 전에는 단일 큐로 idle tick이 없고 오로지 ready list로만 관리된다. kernel단 까지 들어갈 필요가 없는 thread도 block 되지 않고 yield()가 되는게 busy wait 이라는 문제가 된다.
그래서 sleep_list를 만들어 준 뒤에, 당장에 불 필요한 thread들을 sleep 시켜줘야 한다.
void
timer_sleep (int64_t ticks) {
int64_t start = timer_ticks ();
ASSERT (intr_get_level () == INTR_ON);
if(timer_elapsed(start) < ticks){
thread_sleep(start + ticks);
}
}
timer를 활용하여 sleep을 시키는데 이 때 thread를 block시키고, sleep list로 들어가면 해당 자원을 양보시켜줘야한다.
void
thread_sleep(int64_t ticks){
struct thread *curr = thread_current();
enum intr_level old_level;
ASSERT(!intr_context());
old_level = intr_disable();
curr->status = THREAD_BLOCKED;
curr->wakeup_tick = ticks;
if(curr!= idle_thread)
list_insert_ordered(&sleep_list, &curr->elem, sleep_less , NULL);
schedule();
intr_set_level(old_level);
}
sleep을 시켰으니, 적당한 타임이 되면 thread를 깨워줘야한다. 인터럽트가 발생할 때마다, 틱을 증가시키는데, 이 때 thread가 깨어날 타이밍이라면 깨운다.
static void
timer_interrupt (struct intr_frame *args UNUSED) {
ticks++;
thread_tick ();
thread_wakeup(ticks);
}
이 때, 깨울 타임이 같은 thread 중 우선순위가 높은 순서대로 ready_list에 들어가야 우선순위가 높은 thread 부터 실행이 될 수 있다. 고로, sleep된 thread 중 깨웠을 때 greater_list에 우선순위 순으로 정렬해서 넣고 그 greater_list가 ready_list에 들어간다면 될 것 이다.
void
thread_wakeup(int64_t ticks)
{
if(list_empty(&sleep_list))
return;
enum intr_level old_level;
struct thread *sleep_front_thread = list_entry(list_begin(&sleep_list),struct thread, elem);
struct thread *sleep_pop_front_thread;
while(sleep_front_thread->wakeup_tick <= ticks)
{
old_level = intr_disable();
sleep_front_thread->status = THREAD_READY;
sleep_pop_front_thread = list_entry(list_pop_front(&sleep_list), struct thread, elem);
list_insert_ordered(&greater_list, &sleep_pop_front_thread->elem , cmp_priority, NULL);
sleep_front_thread = list_entry(list_begin(&sleep_list),struct thread, elem);
intr_set_level(old_level);
}
while(!list_empty(&greater_list))
{
old_level = intr_disable();
list_push_back(&ready_list, list_pop_front(&greater_list));
intr_set_level(old_level);
}
}
lock_acquire 함수는 주어진 락을 현재 스레드가 획득하려고 시도할 때 호출된다. 이미 누군가 그 락을 가지고 있다면, 현재 스레드는 대기 상태로 들어가게 되며, 락을 보유한 스레드가 lock_release를 호출하여 락을 해제할 때까지 기다려야 한다.
락의 holder가 NULL이 아니라면, 즉 누군가가 이미 락을 보유하고 있다면, 현재 스레드는 대기해야 한다. 이때, 현재 스레드의 우선순위가 락을 보유한 스레드의 우선순위보다 높다면, 우선순위 기부가 발생한다. 우선순위 기부는 락을 보유한 스레드의 우선순위를 현재 스레드의 우선순위로 상향 조정함으로써, 고우선순위 스레드가 더 빨리 실행될 수 있도록 한다.
이미 대기 중인 스레드가 있는 경우, 그 스레드들의 우선순위도 확인하고 필요에 따라 우선순위를 상속시켜 우선순위 역전 문제를 해결한다. 락을 획득할 수 있을 때까지 현재 스레드는 세마포어를 사용하여 대기 상태로 들어가고 sema_down 함수를 호출하여 세마포어의 값을 감소시키고, 필요하다면 스레드를 대기 상태로 만든다.
void
lock_acquire (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (!lock_held_by_current_thread (lock));
if(lock->holder != NULL)
{
thread_current()->wait_on_lock = lock;
if(lock->holder->priority < thread_current()->priority)
{
list_insert_ordered(&lock->holder->donations, &thread_current()->d_elem, sleep_less, NULL);
}
struct lock *cur_wait_on_lock = thread_current()->wait_on_lock;
while(cur_wait_on_lock != NULL)
{
if(cur_wait_on_lock->holder->priority< thread_current()->priority)
{
cur_wait_on_lock->holder->priority = thread_current()->priority;
cur_wait_on_lock = cur_wait_on_lock->holder->wait_on_lock;
}
else
break;
}
}
sema_down (&lock->semaphore);
thread_current()->wait_on_lock = NULL;
lock->holder = thread_current ();
}
sema_down 함수는 세마포어(semaphore)의 값을 감소시키려고 시도하는 연산이다. 세마포어는 동기화 목적으로 사용되는 변수로, 리소스의 사용 가능 여부를 나타낸다. sema_down 함수는 주로 락(lock) 획득이나 자원 접근 제어에 사용된다. 세마포어의 값이 0이면, 이는 해당 리소스가 사용 중임을 의미하며, 어떤 스레드도 리소스를 사용할 수 없다.
sema->value가 0인 경우, 이는 다른 스레드가 이미 리소스를 사용 중임을 의미하므로, 현재 스레드는 대기해야 한다. 이를 위해 현재 스레드는 세마포어의 대기 목록(sema->waiters)에 추가된다. 대기 목록에 추가될 때, 우선순위에 따라 정렬되어 대기 순서가 결정된다. 이후, thread_block 함수를 호출하여 현재 스레드를 대기 상태로 전환한다.
대기 중인 스레드 없이 sema->value가 0보다 큰 경우, 혹은 대기 중인 스레드가 깨어나 세마포어를 사용할 수 있는 경우, sema->value는 1 감소한다. 이는 리소스 하나가 사용 중임을 나타낸다.
void
sema_down (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
ASSERT (!intr_context ());
old_level = intr_disable ();
while (sema->value == 0) {
list_insert_ordered (&sema->waiters, &thread_current ()->elem, cmp_priority, NULL);
thread_block ();
}
sema->value--;
intr_set_level (old_level);
}
lock_release 함수는 스레드가 보유한 락(lock)을 해제하고, 해당 락을 기다리는 다른 스레드들에게 양보한다.
락을 해제하는 스레드(lock->holder)의 우선순위 기부 목록(donations)을 확인하여, 이 락을 기다리고 있던 모든 스레드들의 기부 항목을 제거하고, 우선순위 기부 목록을 순회하면서, 현재 락(lock)을 기다리고 있던(wait_on_lock이 현재 락을 가리키는) 스레드를 찾아 해당 스레드의 d_elem(우선순위 기부 목록에서의 위치를 나타내는 리스트 요소)을 목록에서 제거하고, wait_on_lock을 NULL로 설정한다.(우선순위 기부가 더 이상 필요하지 않음)
우선순위 기부 목록이 비어있지 않다면(다른 스레드들로부터 우선순위 기부를 받고 있는 상황), 목록의 첫 번째 스레드(next_thread)의 우선순위를 현재 스레드의 우선순위로 설정한다.
우선순위 기부 목록이 비어있다면(더 이상 우선순위 기부를 받고 있지 않은 상황), 스레드의 우선순위를 원래의 우선순위(original_priority)로 복원한다.
락의 holder를 NULL로 설정하여, 락의 소유권을 해제하고, sema_up(&lock->semaphore)를 호출하여 세마포어의 값을 1 증가시키고, 세마포어 대기 목록에 있는 스레드 중 하나를 깨운다(있다면). 이는 락이 이제 사용 가능하게 되었음을 나타내며, 대기 중인 스레드가 락을 획득할 수 있게 한다.
void
lock_release (struct lock *lock) {
ASSERT (lock != NULL);
ASSERT (lock_held_by_current_thread (lock));
if(!list_empty(&lock->holder->donations))
{
struct list_elem *front_elem = list_begin(&lock->holder->donations);
while(front_elem != list_end(&lock->holder->donations))
{
struct thread *front_thread = list_entry(front_elem, struct thread, d_elem);
if(front_thread->wait_on_lock == lock)
{
list_remove(&front_thread->d_elem);
front_thread->wait_on_lock = NULL;
}
front_elem = list_next(front_elem);
}
if(!list_empty(&lock->holder->donations))
{
struct thread *next_thread = list_entry(list_front(&lock->holder->donations), struct thread, d_elem);
lock->holder->priority = next_thread->priority;
}
else
lock->holder->priority = lock->holder->original_priority;
}
lock->holder = NULL;
sema_up (&lock->semaphore);
}
세마포어의 대기자 목록(sema->waiters)이 비어있지 않은 경우, 즉 대기 중인 스레드가 있는 경우에는 대기자 목록에서 가장 앞에 있는 스레드(가장 높은 우선순위를 가진 스레드)를 꺼내 thread_unblock 함수를 호출하여 실행 가능 상태로 만들고, 세마포어의 value를 1 증가시킨다. (추가적인 리소스가 사용 가능해졌거나, 더 이상 대기 중인 스레드가 없음)
void
sema_up (struct semaphore *sema) {
enum intr_level old_level;
ASSERT (sema != NULL);
old_level = intr_disable ();
if (!list_empty (&sema->waiters))
{
list_sort(&sema->waiters, cmp_priority, NULL);
thread_unblock (list_entry (list_pop_front (&sema->waiters),
struct thread, elem));
}
sema->value++;
intr_set_level (old_level);
thread_yield();
}
donations가 만약 비어있다면, 현재 스레드의 priority 필드를 새로운 우선순위 값으로 업데이트를 하여 기부를 받고 있지 않을 때만 스레드의 우선순위를 직접 변경할 수 있게 해야한다.
void
thread_set_priority (int new_priority) {
if(list_empty(&thread_current()->donations))
thread_current ()->priority = new_priority;
thread_current ()->original_priority = new_priority;
struct thread *head_thread = list_entry(list_begin(&ready_list), struct thread, elem);
if(head_thread->priority > new_priority)
thread_yield();
}
조건 변수의 대기자 목록이 비어 있지 않다면, 대기자 목록을 우선순위에 따라 정렬해야한다. 대기자 목록(waiters)에서 가장 앞에 있는 세마포어 요소를 꺼내, 그 세마포어를 통해 대기 중인 스레드 중 하나를 깨운다.
void
cond_signal (struct condition *cond, struct lock *lock UNUSED) {
ASSERT (cond != NULL);
ASSERT (lock != NULL);
ASSERT (!intr_context ());
ASSERT (lock_held_by_current_thread (lock));
if (!list_empty (&cond->waiters))
list_sort(&cond->waiters, cmp_condvar_priority, NULL);
sema_up (&list_entry (list_pop_front (&cond->waiters),
struct semaphore_elem, elem)->semaphore);
}
조건 변수의 대기자 목록에 있는 두 개의 세마포어에서 객체를 가져와 두 스레드의 우선순위를 비교하여 첫 번째 스레드가 더 높다면, true 두 번째 스레드가 더 높다면 false를 반환한다.
bool
cmp_condvar_priority(const struct list_elem *a, const struct list_elem *b, void *aux UNUSED) {
struct semaphore_elem *sema_elem_a = list_entry(a, struct semaphore_elem, elem);
struct semaphore_elem *sema_elem_b = list_entry(b, struct semaphore_elem, elem);
struct semaphore sema_a = sema_elem_a->semaphore;
struct semaphore sema_b = sema_elem_b->semaphore;
struct thread *t_a = list_entry(list_begin(&sema_a.waiters), struct thread, elem);
struct thread *t_b = list_entry(list_begin(&sema_b.waiters), struct thread, elem);
return t_a->priority > t_b->priority;
}
extra 문제인 MLFQS 빼고 전부 pass되었다.
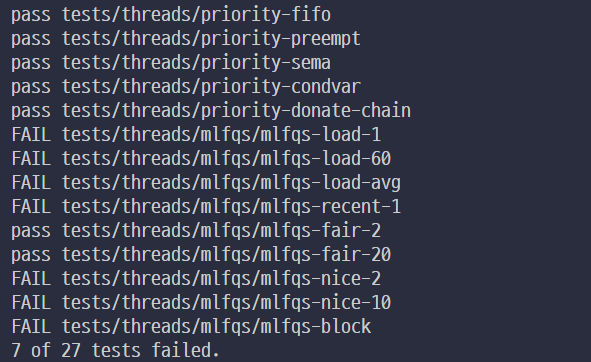
master branch에 project1만 취급하는 코드가 있음
GitHub - yunsejin/PintOS_RE: PintOS_Project1,2,3
PintOS_Project1,2,3. Contribute to yunsejin/PintOS_RE development by creating an account on GitHub.
github.com
'CS > 운영체제' 카테고리의 다른 글
| Demand-zero page, Anonymous page, File-backed page (0) | 2024.03.27 |
|---|---|
| 하이퍼바이저, 애뮬레이션, QEMU (0) | 2024.03.26 |
| Context Switching, Semaphore와 Mutex (2) | 2024.03.25 |
| CPU Scheduling, 4BSD, nice (1) | 2024.03.25 |
| 32bit and 64bit, RAX, CPU vs GPU (1) | 2024.03.24 |